I'm trying to train a Random Forest to classify the species of a set of flowers from the iris dataset. However, the validation looks kind of weird to me, since it looks like the results are perfect, which is something I would not expect.
Since I would like to perform a binary classification, I exclude from the training dataset the flowers whose species belong to the category "2", therefore I have only 0/1 flowers.
Is there something wrong in my code?
from sklearn.datasets import load_iris
from sklearn.ensemble import RandomForestClassifier
from sklearn.model_selection import cross_val_score
iris = load_iris()
X = iris.data
y = iris.target
X = X[y != 2]
y = y[y != 2]
forest = RandomForestClassifier(n_estimators=100, max_depth=2, max_samples=0.7, max_features=2)
print(cross_val_score(forest, X, y, scoring='accuracy'))
Output:
array([1., 1., 1., 1., 1.])
CodePudding user response:
The code is fine, the dataset you have is quite easy to separate, you can visualize this:
import matplotlib.pyplot as plt
fig, ax = plt.subplots(1,2,figsize=(12,6))
ax[0].scatter(X[:,0],X[:,1],c = y)
ax[0].set_xlabel(iris.feature_names[0])
ax[0].set_xlabel(iris.feature_names[1])
ax[1].scatter(X[:,2],X[:,3],c = y)
ax[1].set_xlabel(iris.feature_names[2])
ax[1].set_xlabel(iris.feature_names[3])
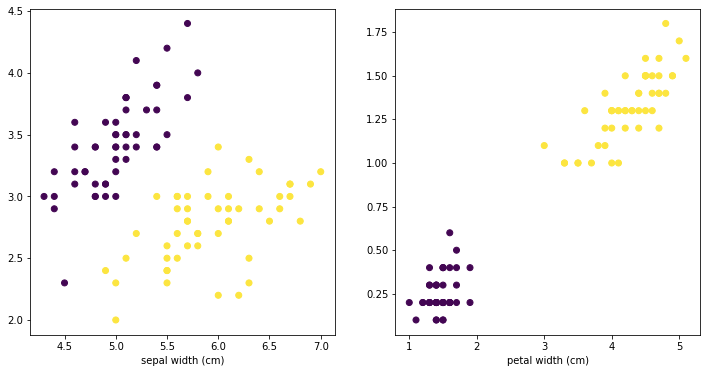
The plot on the right shows your 3rd and 4th column (petal width and length), with the different colors representing different labels. So if you train the data on 80%, you can easily predict correctly the remaining 20% of the validation data, based on setting the right split on the 3rd and 4th column.
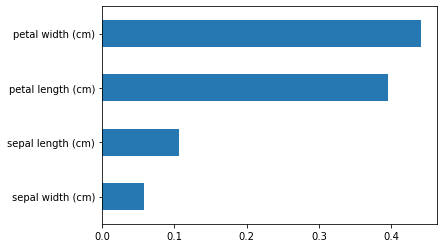
You can also see this with the importance score on 1 of the folds:
from sklearn.model_selection import train_test_split
import pandas as pd
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
forest.fit(X_train,y_train)
importances = pd.Series(forest.feature_importances_,index=iris.feature_names)
importances = importances.sort_values()
importances.plot.barh()