I am trying to obtain all the daily demand curves with a minimum demand of < 400. The data comprises for a whole one year. I want the curves to be grouped by month. Following is my code.
library(lubridate)
library(ggplot2)
library(dplyr)
library(data.table)
library(viridis)
sa <- read.csv("data/SA_demand_data_2020.csv")
sa$SETTLEMENTDATE <- as.POSIXct(strptime(sa$SETTLEMENTDATE, "%d/%m/%Y %H:%M"),
tz="Australia/Queensland")
ts <- sa$SETTLEMENTDATE
# Group sa by date
sa1 <- group_by(sa, date(ts))
#Create a data table with minimum demand for each day (sa2)
sa2=data.table(setDT(sa1)[, .SD[which.min(TOTALDEMAND)], by=date(ts)])
# filter and get only the records having min demand<500
MinDem <- filter(sa2, TOTALDEMAND<400)
#Create a column named "date" in dataframe "sa" having ony date field
sa$date <- date(sa$SETTLEMENTDATE)
# Getting a dataframe/data table which included a coulmn with all demand data for only the days with min demand<500
comb <- merge(MinDem, sa, by.x= "date", by.y="date", all.x=TRUE )
#plot daily demand profile for days with min demand <500
ts <- comb$SETTLEMENTDATE.y
ps <- comb$TOTALDEMAND.y
hs <- hour(ts) minute(ts)/60
ds <-date(ts)
ms <- month(ts)
data <- data.frame(x=hs, y=ps, z=ds, m=ms)
p <- ggplot(data, aes(x=x, y=y, group=z, colour=m))
geom_line( aes(colour=m), size=0.1)
geom_point(aes(colour=m), size=0.2)
scale_colour_viridis_c(option="D")
labs(x="Hour", y="Power (MW)")
scale_x_continuous(breaks = c(0, 3, 6, 9, 12, 15, 18, 21, 24))
scale_y_continuous(limits=c(0, 1600), breaks=seq(0, 1600, by= 100))
theme(legend.position="right")
print(p)
The plot I obtained does not show month names. Instead, it shows a numbered scale. I want to visualize months on the scale
Thanks
The first rows of "sa" data frame look as follows.
structure(list(Source.Name = c("PRICE_AND_DEMAND_202001_SA1.csv",
"PRICE_AND_DEMAND_202001_SA1.csv", "PRICE_AND_DEMAND_202001_SA1.csv",
"PRICE_AND_DEMAND_202001_SA1.csv", "PRICE_AND_DEMAND_202001_SA1.csv",
"PRICE_AND_DEMAND_202001_SA1.csv", "PRICE_AND_DEMAND_202001_SA1.csv",
"PRICE_AND_DEMAND_202001_SA1.csv", "PRICE_AND_DEMAND_202001_SA1.csv",
"PRICE_AND_DEMAND_202001_SA1.csv", "PRICE_AND_DEMAND_202001_SA1.csv",
"PRICE_AND_DEMAND_202001_SA1.csv", "PRICE_AND_DEMAND_202001_SA1.csv",
"PRICE_AND_DEMAND_202001_SA1.csv", "PRICE_AND_DEMAND_202001_SA1.csv",
"PRICE_AND_DEMAND_202001_SA1.csv", "PRICE_AND_DEMAND_202001_SA1.csv",
"PRICE_AND_DEMAND_202001_SA1.csv", "PRICE_AND_DEMAND_202001_SA1.csv",
"PRICE_AND_DEMAND_202001_SA1.csv"), REGION = c("SA1", "SA1",
"SA1", "SA1", "SA1", "SA1", "SA1", "SA1", "SA1", "SA1", "SA1",
"SA1", "SA1", "SA1", "SA1", "SA1", "SA1", "SA1", "SA1", "SA1"
), SETTLEMENTDATE = structure(c(1577802600, 1577804400, 1577806200,
1577808000, 1577809800, 1577811600, 1577813400, 1577815200, 1577817000,
1577818800, 1577820600, 1577822400, 1577824200, 1577826000, 1577827800,
1577829600, 1577831400, 1577833200, 1577835000, 1577836800), class = c("POSIXct",
"POSIXt"), tzone = "Australia/Queensland"), TOTALDEMAND = c(1419.45,
1361.94, 1256.3, 1202.3, 1170.07, 1151.99, 1133.61, 1125.55,
1118.56, 1120.8, 1124.89, 1119.88, 1089.95, 1049.18, 991.23,
927.15, 848.82, 761.16, 686.57, 623.05), RRP = c(68.33, 68.33,
68.76, 68.42, 68.25, 68, 68, 65.65, 60.66, 57.42, 59.95, 56.87,
45.85, 36.27, 42.56, 38.79, 31.55, 6.4, 21.7, 11.32), PERIODTYPE = c("TRADE",
"TRADE", "TRADE", "TRADE", "TRADE", "TRADE", "TRADE", "TRADE",
"TRADE", "TRADE", "TRADE", "TRADE", "TRADE", "TRADE", "TRADE",
"TRADE", "TRADE", "TRADE", "TRADE", "TRADE"), date = structure(c(18262,
18262, 18262, 18262, 18262, 18262, 18262, 18262, 18262, 18262,
18262, 18262, 18262, 18262, 18262, 18262, 18262, 18262, 18262,
18262), class = "Date")), row.names = c(NA, 20L), class = "data.frame")
The first rows of the "comb" dataset look like follows.
structure(list(date = structure(c(18330, 18330, 18330, 18330,
18330, 18330, 18330, 18330, 18330, 18330, 18330, 18330, 18330,
18330, 18330, 18330, 18330, 18330, 18330, 18330), class = "Date"),
Source.Name.x = c("PRICE_AND_DEMAND_202003_SA1.csv", "PRICE_AND_DEMAND_202003_SA1.csv",
"PRICE_AND_DEMAND_202003_SA1.csv", "PRICE_AND_DEMAND_202003_SA1.csv",
"PRICE_AND_DEMAND_202003_SA1.csv", "PRICE_AND_DEMAND_202003_SA1.csv",
"PRICE_AND_DEMAND_202003_SA1.csv", "PRICE_AND_DEMAND_202003_SA1.csv",
"PRICE_AND_DEMAND_202003_SA1.csv", "PRICE_AND_DEMAND_202003_SA1.csv",
"PRICE_AND_DEMAND_202003_SA1.csv", "PRICE_AND_DEMAND_202003_SA1.csv",
"PRICE_AND_DEMAND_202003_SA1.csv", "PRICE_AND_DEMAND_202003_SA1.csv",
"PRICE_AND_DEMAND_202003_SA1.csv", "PRICE_AND_DEMAND_202003_SA1.csv",
"PRICE_AND_DEMAND_202003_SA1.csv", "PRICE_AND_DEMAND_202003_SA1.csv",
"PRICE_AND_DEMAND_202003_SA1.csv", "PRICE_AND_DEMAND_202003_SA1.csv"
), REGION.x = c("SA1", "SA1", "SA1", "SA1", "SA1", "SA1",
"SA1", "SA1", "SA1", "SA1", "SA1", "SA1", "SA1", "SA1", "SA1",
"SA1", "SA1", "SA1", "SA1", "SA1"), SETTLEMENTDATE.x = structure(c(1583726400,
1583726400, 1583726400, 1583726400, 1583726400, 1583726400,
1583726400, 1583726400, 1583726400, 1583726400, 1583726400,
1583726400, 1583726400, 1583726400, 1583726400, 1583726400,
1583726400, 1583726400, 1583726400, 1583726400), tzone = "Australia/Queensland", class = c("POSIXct",
"POSIXt")), TOTALDEMAND.x = c(388.59, 388.59, 388.59, 388.59,
388.59, 388.59, 388.59, 388.59, 388.59, 388.59, 388.59, 388.59,
388.59, 388.59, 388.59, 388.59, 388.59, 388.59, 388.59, 388.59
), RRP.x = c(0.05, 0.05, 0.05, 0.05, 0.05, 0.05, 0.05, 0.05,
0.05, 0.05, 0.05, 0.05, 0.05, 0.05, 0.05, 0.05, 0.05, 0.05,
0.05, 0.05), PERIODTYPE.x = c("TRADE", "TRADE", "TRADE",
"TRADE", "TRADE", "TRADE", "TRADE", "TRADE", "TRADE", "TRADE",
"TRADE", "TRADE", "TRADE", "TRADE", "TRADE", "TRADE", "TRADE",
"TRADE", "TRADE", "TRADE"), `date(ts)` = structure(c(18330,
18330, 18330, 18330, 18330, 18330, 18330, 18330, 18330, 18330,
18330, 18330, 18330, 18330, 18330, 18330, 18330, 18330, 18330,
18330), class = "Date"), Source.Name.y = c("PRICE_AND_DEMAND_202003_SA1.csv",
"PRICE_AND_DEMAND_202003_SA1.csv", "PRICE_AND_DEMAND_202003_SA1.csv",
"PRICE_AND_DEMAND_202003_SA1.csv", "PRICE_AND_DEMAND_202003_SA1.csv",
"PRICE_AND_DEMAND_202003_SA1.csv", "PRICE_AND_DEMAND_202003_SA1.csv",
"PRICE_AND_DEMAND_202003_SA1.csv", "PRICE_AND_DEMAND_202003_SA1.csv",
"PRICE_AND_DEMAND_202003_SA1.csv", "PRICE_AND_DEMAND_202003_SA1.csv",
"PRICE_AND_DEMAND_202003_SA1.csv", "PRICE_AND_DEMAND_202003_SA1.csv",
"PRICE_AND_DEMAND_202003_SA1.csv", "PRICE_AND_DEMAND_202003_SA1.csv",
"PRICE_AND_DEMAND_202003_SA1.csv", "PRICE_AND_DEMAND_202003_SA1.csv",
"PRICE_AND_DEMAND_202003_SA1.csv", "PRICE_AND_DEMAND_202003_SA1.csv",
"PRICE_AND_DEMAND_202003_SA1.csv"), REGION.y = c("SA1", "SA1",
"SA1", "SA1", "SA1", "SA1", "SA1", "SA1", "SA1", "SA1", "SA1",
"SA1", "SA1", "SA1", "SA1", "SA1", "SA1", "SA1", "SA1", "SA1"
), SETTLEMENTDATE.y = structure(c(1583676000, 1583677800,
1583679600, 1583681400, 1583683200, 1583685000, 1583686800,
1583688600, 1583690400, 1583692200, 1583694000, 1583695800,
1583697600, 1583699400, 1583701200, 1583703000, 1583704800,
1583706600, 1583708400, 1583710200), class = c("POSIXct",
"POSIXt"), tzone = "Australia/Queensland"), TOTALDEMAND.y = c(1249.56,
1251.44, 1212.15, 1123.59, 1086.58, 1046.36, 1029.07, 1018.48,
1020.76, 1016.86, 1041.95, 1035.11, 1062.83, 1077.97, 1085.84,
1078.29, 1003.12, 918.83, 841.33, 743.89), RRP.y = c(20.97,
7.01, 9.78, 6.23, 0.25, 0, 1.05, 0, 4.3, 10.76, 15.85, 32.4,
26.05, 47.78, 63.66, 40.15, 35.51, 32.26, 13.07, 9.45), PERIODTYPE.y = c("TRADE",
"TRADE", "TRADE", "TRADE", "TRADE", "TRADE", "TRADE", "TRADE",
"TRADE", "TRADE", "TRADE", "TRADE", "TRADE", "TRADE", "TRADE",
"TRADE", "TRADE", "TRADE", "TRADE", "TRADE")), class = c("data.table",
"data.frame"), row.names = c(NA, -20L), .internal.selfref = <pointer: 0x000001fc25e71ef0>, sorted = "date")
CodePudding user response:
One option to achieve your desired result is to set the labels of the color scale via labels = ~ month.name[.x] which converts months from numbers to names:
library(ggplot2)
library(viridis)
#> Loading required package: viridisLite
ggplot(data, aes(x = x, y = y, group = z, colour = m))
geom_line(aes(colour = m), size = 0.1)
geom_point(aes(colour = m), size = 0.2)
scale_colour_viridis_c(option = "D", labels = ~month.name[.x])
labs(x = "Hour", y = "Power (MW)")
scale_x_continuous(breaks = c(0, 3, 6, 9, 12, 15, 18, 21, 24))
scale_y_continuous(limits = c(0, 1600), breaks = seq(0, 1600, by = 100))
theme(legend.position = "right")
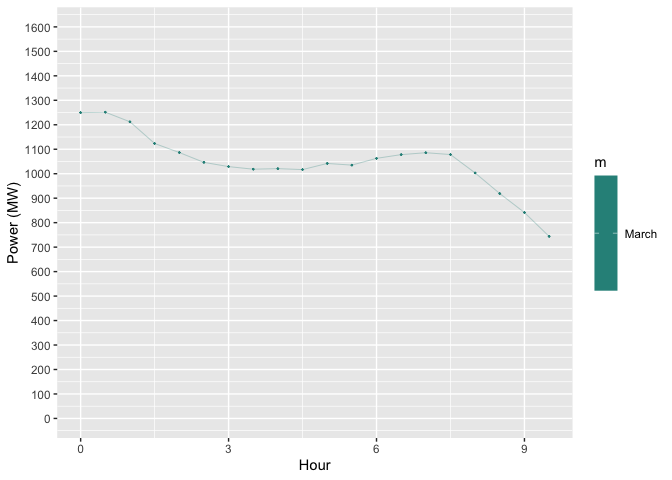
DATA
data <- structure(list(x = c(
0, 0.5, 1, 1.5, 2, 2.5, 3, 3.5, 4, 4.5,
5, 5.5, 6, 6.5, 7, 7.5, 8, 8.5, 9, 9.5
), y = c(
1249.56, 1251.44,
1212.15, 1123.59, 1086.58, 1046.36, 1029.07, 1018.48, 1020.76,
1016.86, 1041.95, 1035.11, 1062.83, 1077.97, 1085.84, 1078.29,
1003.12, 918.83, 841.33, 743.89
), z = structure(c(
18330, 18330,
18330, 18330, 18330, 18330, 18330, 18330, 18330, 18330, 18330,
18330, 18330, 18330, 18330, 18330, 18330, 18330, 18330, 18330
), class = "Date"), m = c(
3L, 3L, 3L, 3L, 3L, 3L, 3L, 3L, 3L,
3L, 3L, 3L, 3L, 3L, 3L, 3L, 3L, 3L, 3L, 3L
)), class = "data.frame", row.names = c(
NA,
-20L
))