My data looks like this:
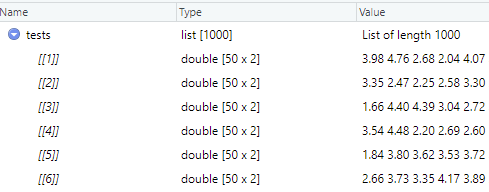
I'm trying to make create a dataset using only the 2nd column of every list element, is there a better way other than using for loops?
CodePudding user response:
A for loop will work, but this a better job for lapply.
I changed the columns to rows and combined them into a 1000 x 50 matrix.
I made up my own data, since you didn't provide any.
set.seed(42)
tests <- replicate(1000, list(matrix(runif(100), ncol = 2)))
m <- do.call('rbind', lapply(tests, function(x) x[, 2]))
dim(m)
[1] 1000 50
head(m[, 1:5])
[,1] [,2] [,3] [,4] [,5]
[1,] 0.3334272 0.3467482 0.3984854 0.7846928 0.03893649
[2,] 0.7193786 0.3240860 0.7788095 0.3944410 0.67859287
[3,] 0.3342313 0.1884343 0.2697162 0.5307441 0.02145023
[4,] 0.4400762 0.5763365 0.0736678 0.1646274 0.73989078
[5,] 0.4309256 0.3968551 0.6969568 0.6593197 0.40735071
[6,] 0.9048984 0.1991984 0.6809630 0.1375178 0.10699469