I am trying to match a pattern where it should be 10 character long and shall have spaces in between.
2021.11.17 12:41:56.124, #cef4df4e CB 1111: Field value 0 for field is out of numeric range according to AABCAKKA01 from ABCD 1111
2021.11.17 12:42:57.225, #cef4df4e BC 1234: Field value 0 for field is out of numeric range according to AABCAKKB02
2021.11.17 12:42:57.421, #cef4df4e CC 1231: This is from JDBS 234 according to AABCAKKB02
2021.11.17 12:42:58.125, #cef4df4e AC 1224: Field value 0 for field is out of numeric range according to AABCAKKB02 from JDBS 11
When I try the below regex, I am able to match the necessary, but also matching the pattern I do not want (which is still right, but I want to get rid of those matches).
\s ([A-Z0-9 ]{10})
I want to match only "ABCD 1111", "JDBS 234" and "JDBS 11". But I am also getting "AABCAKKB02" and "AABCAKKA01"
Any suggestion or help please? Thank you.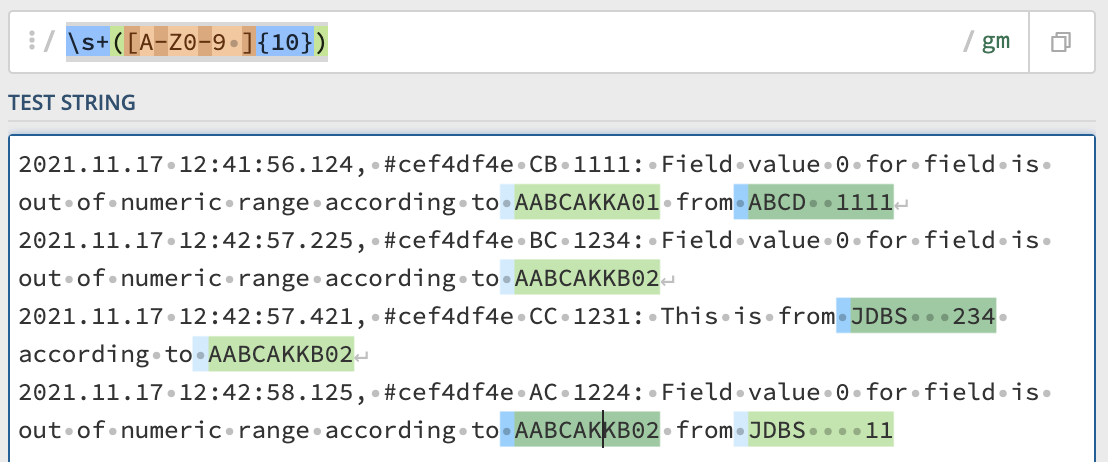
CodePudding user response:
You may use this regex:
\b(?=[A-Z\d ]{10}\b)[A-Z] (?: [A-Z\d] )*\b
RegEx Details:
\b: Word boundary(?=.{10}\b): Lookahead to assert that we have 10 characters of alphanumerics or spaces ahead of the current position[A-Z]: Match 1 uppercase letter(?: [A-Z\d] )*: Match 1 spaces followed by 1 of alphanumerics. Repeat this group 0 or more times.\b: Word boundary
CodePudding user response:
With your shown samples only, please try following regex. This uses PCRE regex concepts of lazy match.*? and \K option(to forget previous matched values; so that we get only matched ones).
.*?from\s \K[A-Za-z \d]{10}
Explanation: Adding detailed explanation for above.
.*?from\s \K ##Matching everything(as a lazy match) till from(word) followed by spaces(1 or more occurrences)
##then using \K option to forget this match to get only next matched values in output.
[A-Za-z \d]{10} ##Matching capital/small letters with space and digits 10 in numbers here as per OP's requirement.