I have commas in a column which I want to remove using regex.This link shows how to do so. The problem is I am getting this error in the image. The documenation says it must be a string, which mine is as you can see in the dtypes. If this is True then to_replace must be a string. Why I am I still getting this error? Thanks! 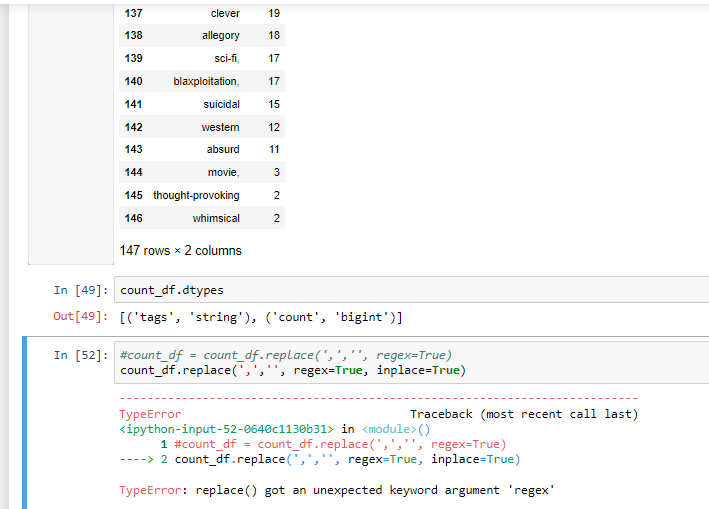
CodePudding user response:
Your current syntax for calling replace on the entire data frame looks correct to me. The problem may be that the count column is numeric, and hence it makes no sense to be calling replace on it. Try calling replace only on the tags column:
count_df["tags"] = count_df["tags"].str.replace(',', '')
CodePudding user response:
from pyspark.sql.functions import udf, concat, col, lit
import re
commaRep = udf(lambda x: re.sub(',$|^,','', x))
count_df_2=count_df.withColumn('tags',commaRep('tags'))
count_df_2.show(3)