I have a dataframe that shows each audience's ranking for a bunch of movies. I wanted to make a list of movies with the most ratings, for each gender. Here's what I did:
most_rated_gen=lens.groupby(['sex','title']).size().sort_values(ascending=False).to_frame()
I was expecting to see a dataframe that looks something like this:
sex | title
M A
B
C
D
F B
C
D
A
Instead, I got this:
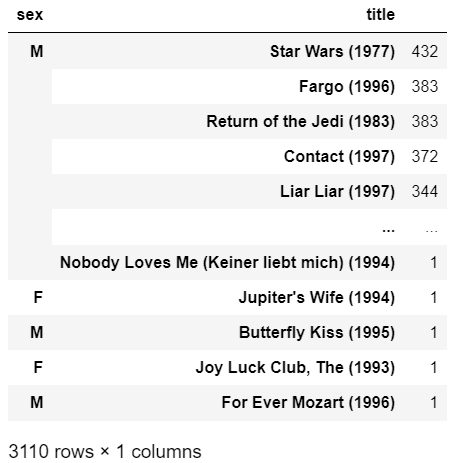
I don't know why it shows M F M F M. Any ideas how I could fix this?
CodePudding user response:
As you group by sex, the output will contain the sex column.
You have a shortcut for your operation with value_counts:
df.value_counts(['sex', 'title']).sort_index(kind='mergesort')
If you want your data to be sorted by index while preserving the order of values then you have to use sort_index with kind='mergesort' as parameter.
CodePudding user response:
You can use nlargest() if your aggregated column has a name. Assuming the column name is ratings_count. You can use this code.
most_rated_gen.groupby(['sex'])['ratings_count'].nlargest()