I'm trying to read in a table from a website, but when I do this, I am getting a result from the website that says: "It appears your browser may be outdated. For the best website experience, we recommend updating your browser."
I am able to use requests.get on the Stats portion of this same PGA website without issue, but for some reason the way these historical results tables are displayed it is causing issues. One interesting thing going on is the web site allows you to select different years for the displayed table, but doing that doesn't result in any difference to the address, so I suspect they are formatting it in a way that read_html won't work. Any other suggestions? Code below.
import pandas as pd
import requests
farmers_url = 'https://www.pgatour.com/tournaments/farmers-insurance-open/past-results.html'
farmers = pd.read_html(requests.get(farmers_url).text, header=0)[0]
farmers.head()
CodePudding user response:
I see a request to the following file for the content you want. This would otherwise be an additional request made by the browser from your start url. What you are currently getting is the actual content of a table at the requested url prior to any updates which would happen dynamically with a browser.
import requests
import pandas as pd
headers = {'User-Agent': 'Mozilla/5.0'}
r = requests.get('https://www.pgatour.com/tournaments/farmers-insurance-open/past-results/jcr:content/mainParsys/pastresults.selectedYear.2021.004.html', headers=headers).text
pd.read_html(r)
If you want to do tidying to look like the actual webpage then something like the following transformations and cleaning:
import requests
import pandas as pd
headers = {'User-Agent': 'Mozilla/5.0'}
r = requests.get('https://www.pgatour.com/tournaments/farmers-insurance-open/past-results/jcr:content/mainParsys/pastresults.selectedYear.2021.004.html', headers=headers).text
t = pd.read_html(r)[0]
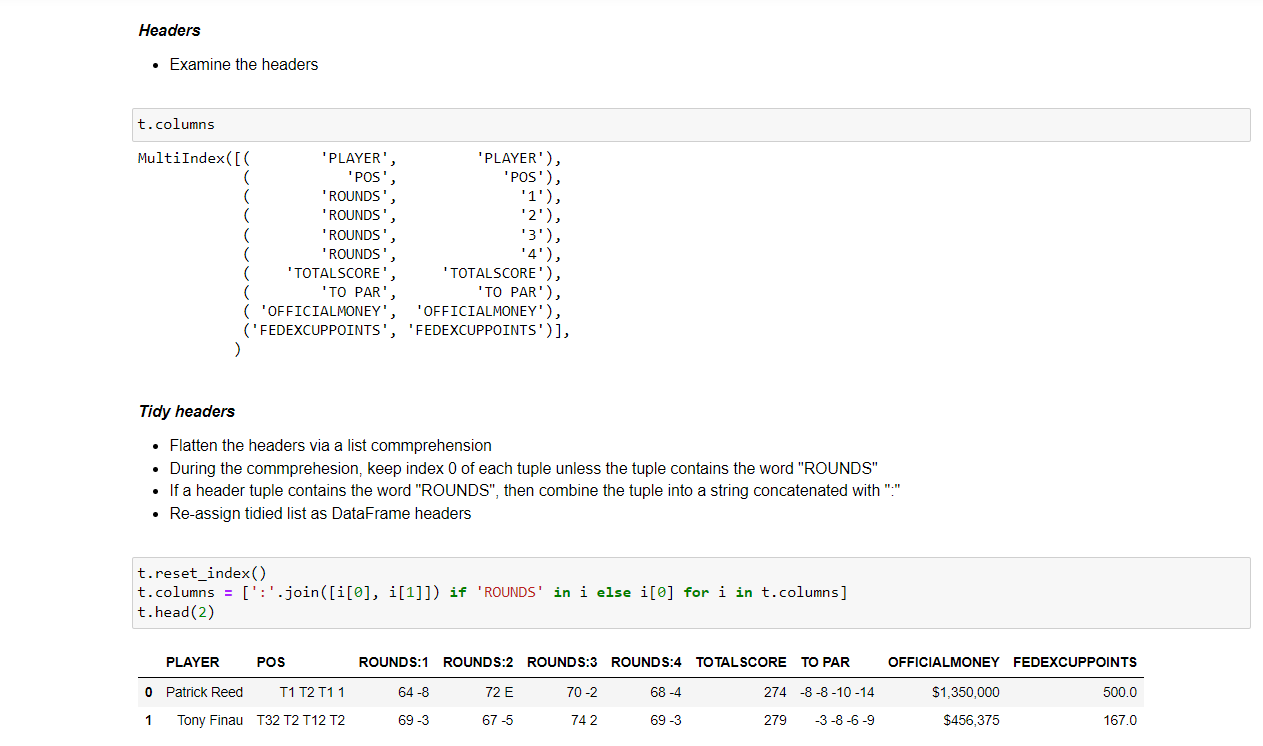
t.reset_index()
t.columns = [':'.join([i[0], i[1]]) if 'ROUNDS' in i else i[0] for i in t.columns]
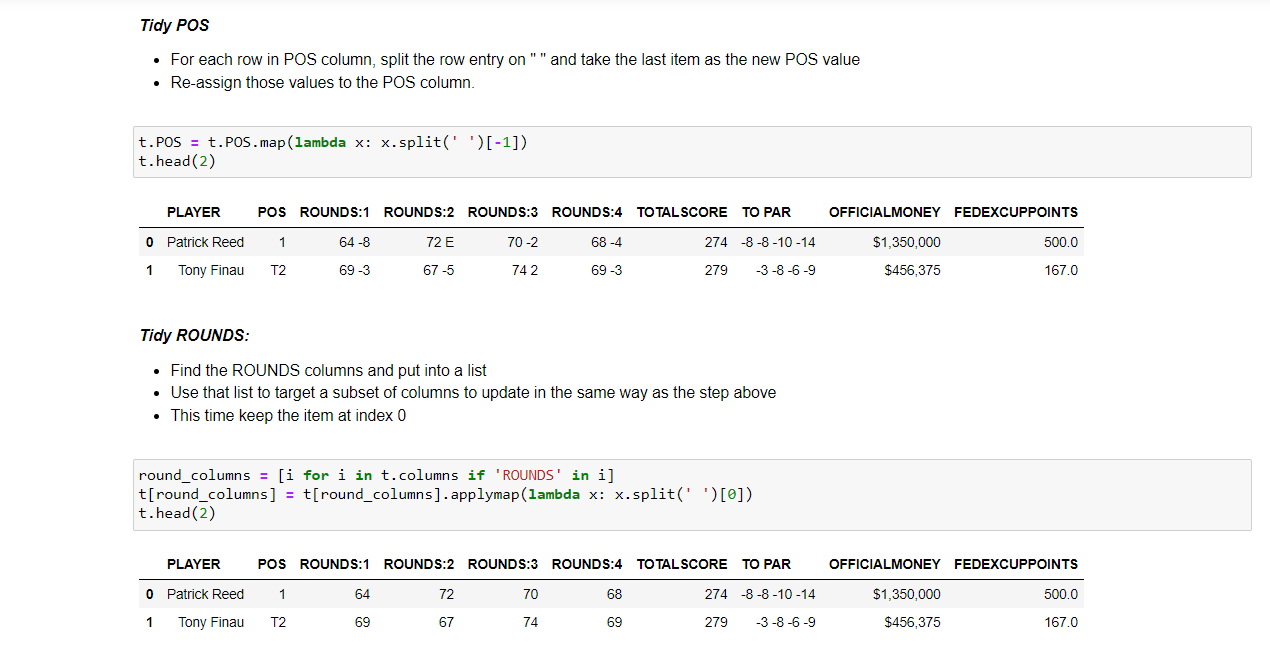
t.POS = t.POS.map(lambda x: x.split(' ')[-1])
round_columns = [i for i in t.columns if 'ROUNDS' in i]
t[round_columns] = t[round_columns].applymap(lambda x: x.split(' ')[0])
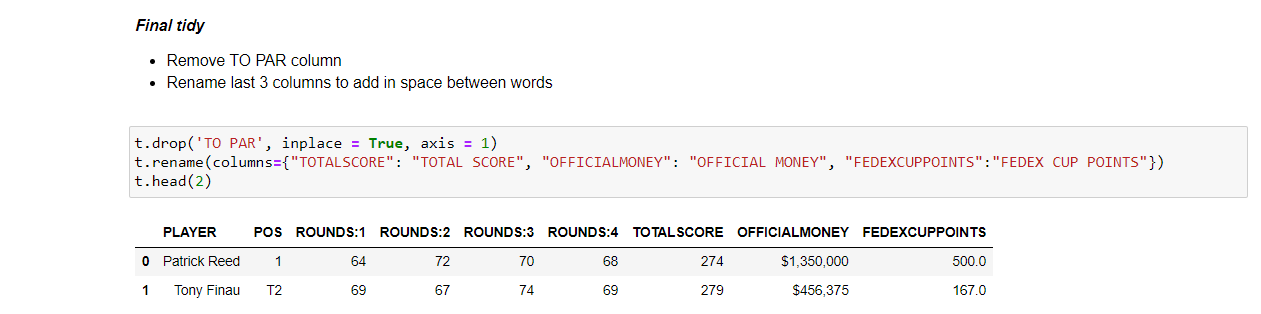
t.drop('TO PAR', inplace = True, axis = 1)
t.rename(columns={"TOTALSCORE": "TOTAL SCORE", "OFFICIALMONEY": "OFFICIAL MONEY", "FEDEXCUPPOINTS":"FEDEX CUP POINTS"})
Detail: