I got about ten thousand data points from the sensor. This data was extracted as an excel .csv file and loaded using readtable, resulting in a 10093x1 table.
However, the problem I am experiencing is that the 1st, 10th, 19th, etc., of these data are unnecessary values, so I want to exclude them. I've found that these numbers have one thing in common: a row with a remainder of 1 when divided by 9.
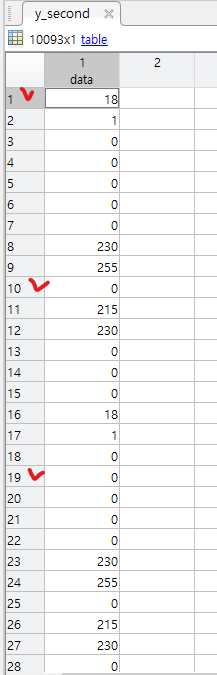
How can I remove the rows where the divisor with 9 equals 1?
CodePudding user response:
You're just removing every ninth row, so you can even use simple colon indexing
data(1:9:end, :) = [];
Alternatively, using your divisor theory, you can do this by using mod() and logical indexing:
idxRemove = mod(1:size(data,1),9) == 1; % True if remainder after division by 9 is 1
data(idxRemove,:) = []; % Remove unwanted rows
You can one-line it for efficiency, since idxRemove isn't stored in that case:
data(mod(1:size(data,1),9) == 1,:) = [];
In either way, using mod() will be slower and less readable than using the colon indexing.