I need to transform a data frame into what I think are adjacency matrices or some sort of pivot table using a datetime column. I have tried a lot of googling but haven't found anything, so any help in how to do this or even what I should be googling would be appreciated.
Here is a simplified version of my data:
df = pd.DataFrame({'Location' : [1]*7 [2]*7,
'Postcode' : ['XXX XXX']*7 ['YYY YYY']*7,
'Date' : ['03-12-2021', '04-12-2021', '05-12-2021', '06-12-2021', '07-12-2021',
'08-12-2021', '09-12-2021', '03-12-2021', '04-12-2021', '05-12-2021',
'06-12-2021', '07-12-2021', '08-12-2021', '09-12-2021'],
'Var 1' : [6.9, 10.2, 9.2, 7.6, 9.8, 8.6, 10.6, 9.9, 9.4, 9, 9.4, 9.1, 8, 9.9],
'Var 2' : [14.5, 6.2, 9.7, 12.7, 14.8, 12, 12.2, 12.3, 14.2, 13.8, 11.7, 17.8,
10.7, 12.3]})
df['Date'] = pd.to_datetime(df['Date'], dayfirst=True)
Location Postcode Date Var 1 Var 2
0 1 XXX XXX 2021-12-03 6.9 14.5
1 1 XXX XXX 2021-12-04 10.2 6.2
2 1 XXX XXX 2021-12-05 9.2 9.7
3 1 XXX XXX 2021-12-06 7.6 12.7
4 1 XXX XXX 2021-12-07 9.8 14.8
5 1 XXX XXX 2021-12-08 8.6 12.0
6 1 XXX XXX 2021-12-09 10.6 12.2
7 2 YYY YYY 2021-12-03 9.9 12.3
8 2 YYY YYY 2021-12-04 9.4 14.2
9 2 YYY YYY 2021-12-05 9.0 13.8
10 2 YYY YYY 2021-12-06 9.4 11.7
11 2 YYY YYY 2021-12-07 9.1 17.8
12 2 YYY YYY 2021-12-08 8.0 10.7
13 2 YYY YYY 2021-12-09 9.9 12.3
The output I want to create is what each variable will be in 1, 2, 3 etc days from the Date variable, so it would look like this:
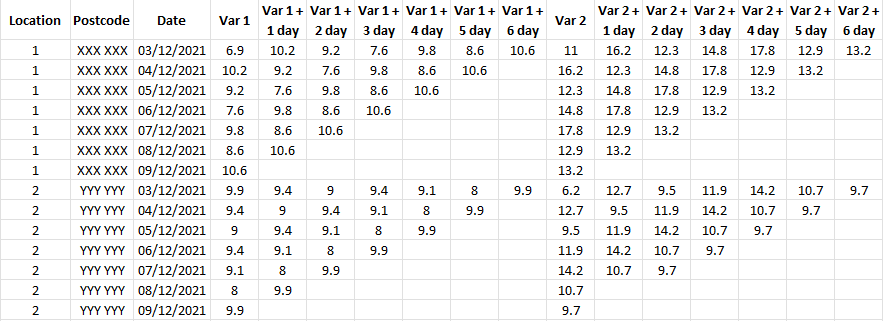
But I have no idea how or where to start. My only thought is several for loops but in reality I have hundreds of locations and 10 variables for 14 Dates each, so it is a large dataset and this would be very inefficient. I feel like there should be a function or simpler way to achieve this.
CodePudding user response:
Create DatetimIndex and then use DataFrameGroupBy.shift withadd suffix by DataFrame.add_suffix with {i:02} for 01, 02..10, 11 for correct sorting columns names in last step:
df = df.set_index('Date')
for i in range(1,7):
df = df.join(df.groupby('Location')[['Var 1', 'Var 2']].shift(freq=f'-{i}d')
.add_suffix(f' Day {i:02}'), on=['Location','Date'])
df = df.set_index(['Location','Postcode'], append=True).sort_index(axis=1)