I had created a script to scrape the data from 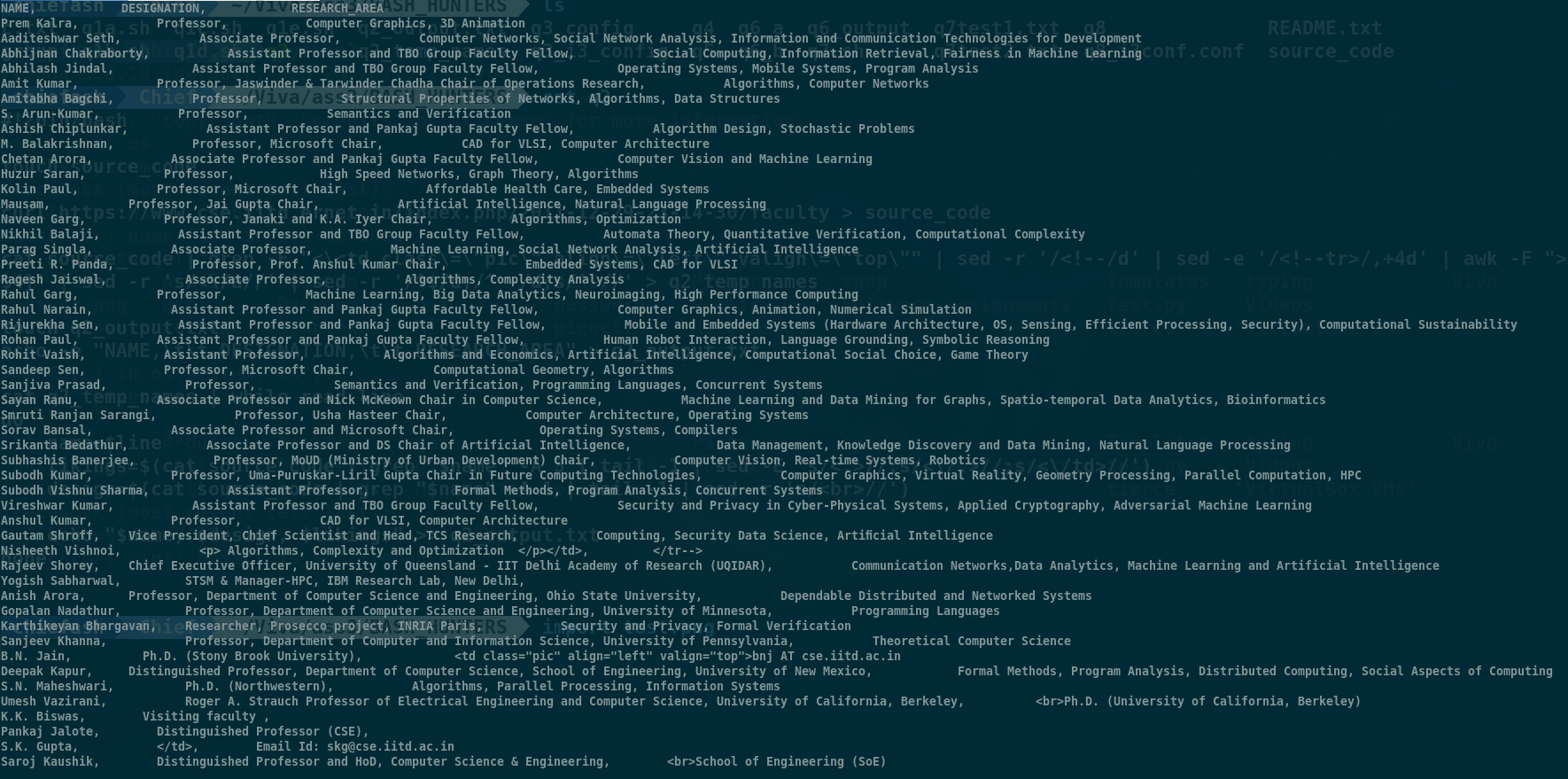
I am sorry the output is very messy, I am new to using these tools.
The output should be a list such that:
Professor's Name Designation Research Area
Prem Kalra Professor Computer Graphics, and 3D graphics
Aaditeshwar Seth Associate Professor Computer Networks, Social Network Analysis,Information and Communication Technologies for Development
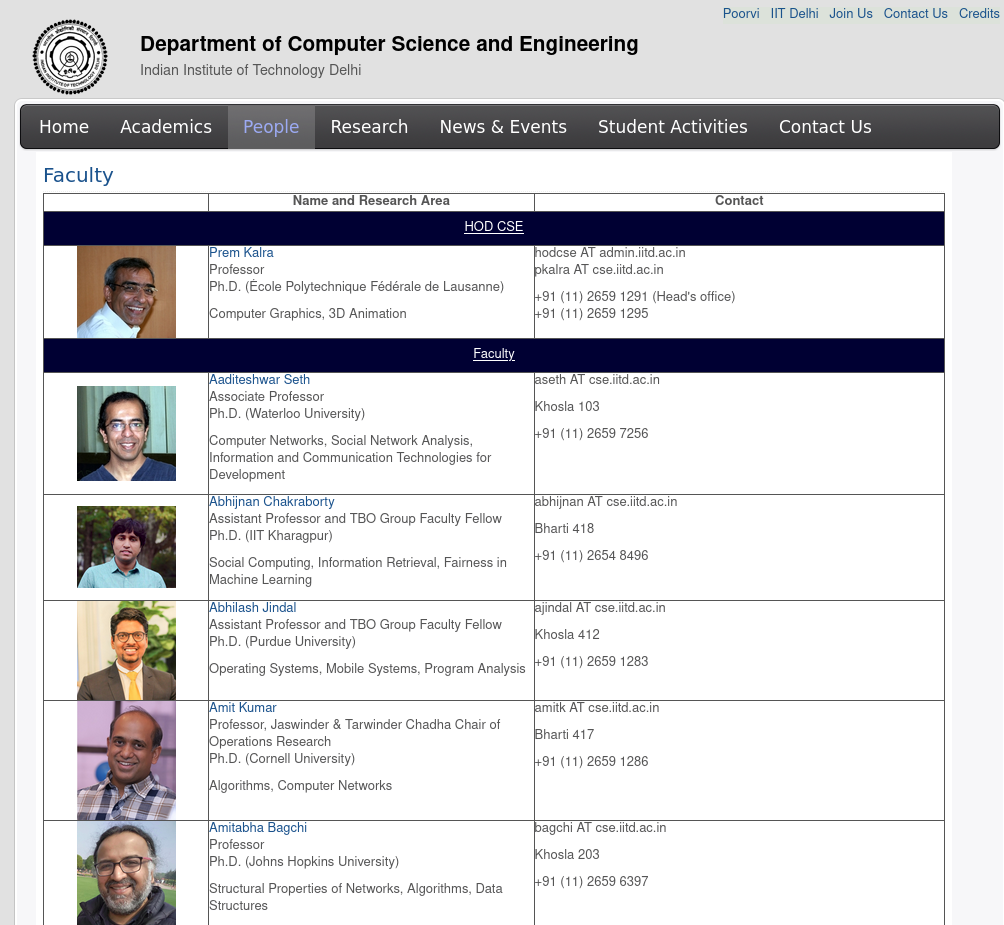
Problems with this script:
- Some professors aren't being scraped from the website. (due to the weird syntax in html)
- Some professor's designation and research area is wrong as the pattern isn't fixed throughout the website.
There are similar such problems
Thanks for any help! Please don't devote
CodePudding user response:
None of the tools you mention (sed/awk/grep/bash) are really able to properly deal with HTML; it is a complex format that really should be parsed.
Clutching it using regular expressions sometimes works out, but especially when you don't control the source application, and plan to redo/refresh your dataset as time passes, there will always be a million ways it can silently break (and you have no real way to test/prepare for it).
There are plenty of other tools that would be more useful, if using that is an option ?
Selenium is a popular choice, there are other questions on this site that basically solve the same problem using that one.
Any of the modern scripting languages are better choices too. PHP (the cli version) is generally available on all linux platforms and comes with native html parsing. I'm sure python, javascript and others do as well.
I'm sure it wouldn't take more than a few lines to parse the html, select the relevant <table> and iterate over all the rows in it (in any of these options really).
CodePudding user response:
Although this is likely possible solely using tools found in bash and shell scripting, it is much easier to use a more robust language such as python. In python, there are libraries such as BeautifulSoup4 that make parsing html much easier and other handy tricks that make string manipulation easier.
I have attached the following code to help parse the website you provided. At the bottom, I am printing the output to stdout although you could also write it to a file.
import requests
from bs4 import BeautifulSoup
url = "https://www.cse.iitd.ernet.in/index.php/2011-12-29-23-14-30/faculty"
res = requests.get(url)
soup = BeautifulSoup(res.text, "html.parser")
entries = soup.find_all("tr")
for i in entries:
cols = i.find_all("td")
if len(cols) == 3:
info = cols[1].find_all("p")
if len(info) == 2:
research_area = info[1].text.strip()
else:
research_area = None
name_and_title = info[0].text.strip().split("\n")
if len(name_and_title) > 1:
title = name_and_title[1]
else:
title = None
name = name_and_title[0]
print(f"{name}, {title}, {research_area}")
Hopefully this is helpful and you are able to solve the problem you are working on.