I have the df which has index with dates and values 0 or 1. I need to filter every first 1 from this data frame. For example:
2019-11-27 0
2019-11-29 0
2019-12-02 0
2019-12-03 1
2019-12-04 1
2019-12-05 1
2020-06-01 0
2020-06-02 0
2020-06-03 1
2020-06-04 1
2020-06-05 1
So I want to get:
2019-12-03 1
2020-06-03 1
CodePudding user response:
Assuming you want the first date with value 1 of the dataframe ordered by date ascending, a window operation might be the best way to do this:
df['PrevValue'] = df['value'].rolling(2).agg(lambda rowset: int(rowset.iloc[0]))
This line of code adds an extra column named "PrevValue" to the dataframe containing the value of the previous row or "NaN" for the first row.
Next, you could query the data as follows:
df_filtered = df.query("value == 1 & PrevValue == 0")
Resulting in the following output:
date value PrevValue
3 2019-12-03 1 0.0
8 2020-06-03 1 0.0
CodePudding user response:
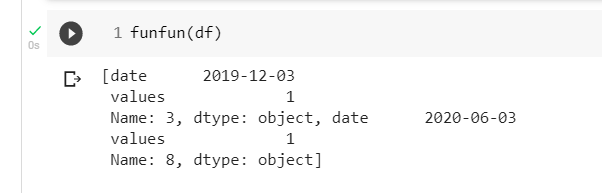
i built function that can satisfy your requirements
important note you should change the col argument it might cause you problem
def funfun (df , col="values"):
'''
df : dataframe
col (str) : please insert the name of column that you want to scan
'''
a = []
c = df.to_dict()
for i in range (len(c[col]) -1 ) :
b=c[col][i] , c[col][i 1]
if b == (0, 1) :
a.append(df.iloc[i 1])
return a
results