Crawl the location of the

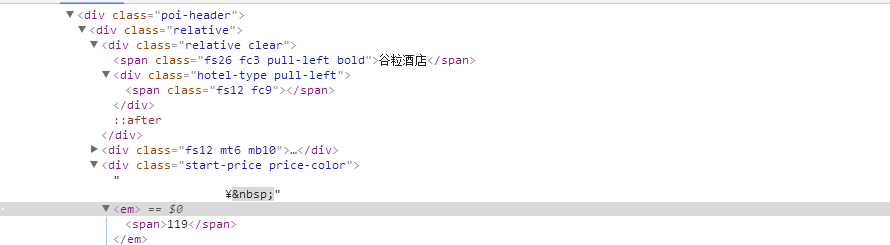
Grab the text should be the price, but the output is 0
Code is the
The from urllib. Request the import urlopen
The from bs4 import BeautifulSoup
Lii="http://hotel.meituan.com/item/161066061/?ci=2017-10-20&co=2017-10-21", "http://hotel.meituan.com/item/5651700/?ci=2017-10-20&co=2017-10-21"]
For ss in lii:
Url=urlopen (ss)
Soup=BeautifulSoup (url. The read (), "LXML")
UI=soup. Find_all (" span ", {" class ":" fs26 fc3 pull - left bold "})
Score=soup. Select (" # poiDetail & gt; Div & gt; Div & gt; Div. The base - the info & gt; Div & gt; Div. Relative ")
For the name in score:
Print (name. Get_text ())
Is fetching in the right way?
CodePudding user response:
I also encountered similar problems, a web page or copy the selector or xpath can export, some were empty,I crawl netease news home page ads, https://news.163.com/
the from requests_html import HTMLSession
The session=HTMLSession ()
Url='https://news.163.com/'
R=session. Get (url)
Sel='//* [@ id="index2016_wrap"]/div [1]/div [2]/div [2]/div [1]/div/iframe/HTML/body/a'
Results=r.h. the TML. Xpath (sel)
Print (results. The HTML. Text)
