The class TestClass extends the Serializable {
Val map=map [String, String] ();
Private def addItem (s: String) {
Val sArr=s.s plit (", ");
The map (sArr (0))=sArr (1);
Println (" * * * the TEST item added: "+ sArr (0) +" - & gt;" + sArr (1));
Println (" * * * the TEST map size: "+ map. The size).
}
Def test () {
Val itemsFile=spark. SparkContext. TextFile ("./items. TXT ");
ItemsFile. Foreach (addItem (_));
//the problem: downward code output is zero!
Println (" * * * the TEST map size is "+ map. The size).
}
}
AddItem () is a (K, v) is applied to a class member variables in the map, the test is meant (), read in a file (inside each row is a (K, v) for) to RDD, then process each line, add the corresponding (K, v) to the class member variables in the map,
Call the test (), you can see addItem () is called success, every time a class member variables have grown the size of the map, but to enforce the last line of code, the map is empty! The size of 0,,,
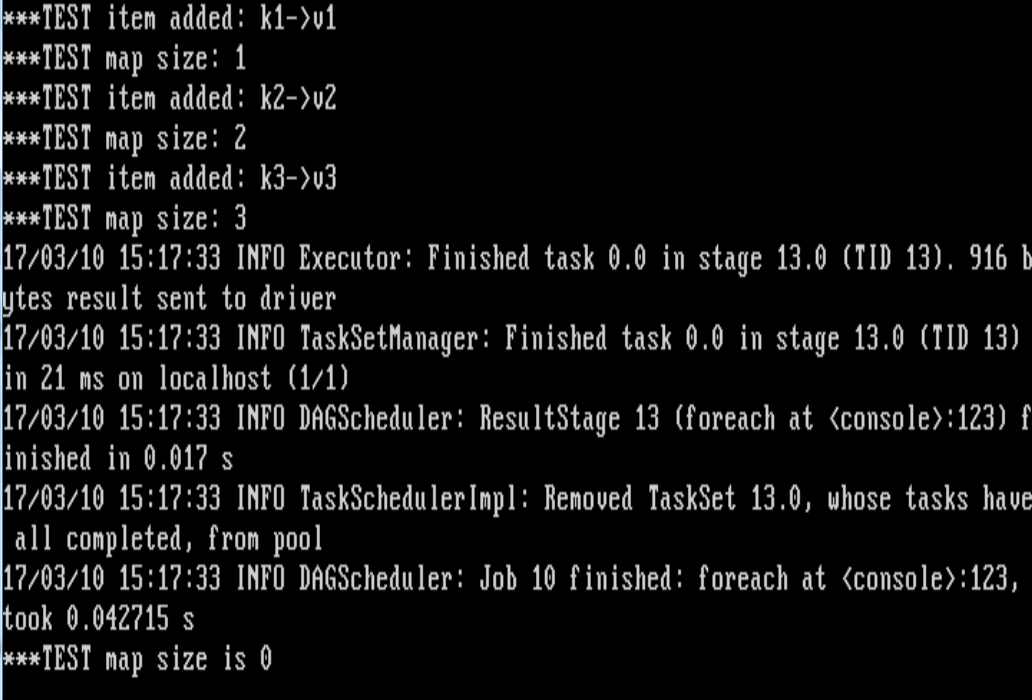
Note: if I don't have to define a class to implement, but directly write additem, test method, is good at running,
Ask why? How to solve? Thank you very much!
CodePudding user response:
You misunderstand the distribution fancy in Spark.The map instance running in your method addItem () is NOT The same as in your driver, which you try to print in The test ().
Change your code to print the map instance identityHashCode will prove it:
The class TestClass extends the Serializable {
Val map=map [String, String] ();
Private def addItem (s: String) {
Val sArr=s.s plit (", ");
The map (sArr (0))=sArr (1);
Println (" * * * the TEST item added: "+ sArr (0) +" - & gt;" + sArr (1));
Println (" * * * the TEST map size: "+ map. The size).
Println (" s "identityHashCode of map is ${System. IdentityHashCode (map)
")}
Def test () {
Val itemsFile=spark. SparkContext. TextFile ("./items. TXT ");
ItemsFile. Foreach (addItem (_));
//the problem: downward code output is zero!
Println (" * * * the TEST map size is "+ map. The size).
Println (" s "identityHashCode of map is ${System. IdentityHashCode (map)
")}
}
See the 2 lines, I added the when you run in the cluster, you will find the identityHashCode printed in 2 the methods are NOT the same.
CodePudding user response:
Thank you for your reply! So how do I get a spark deal? (that is, the test () method in itemsFile. Foreach (addItem (_)))First learning to spark the spark, indeed, the running mechanism, nature poorly understood, but with the spark of distributed processing ability to deal with variables, but not convenient to keep as a result, feel the spark should provide relevant mechanism so that more convenient ah,
CodePudding user response:
Spark can keep the results, of course. I will demo in English, hope you don 't mind, as typing Chinese is too missile for me.You basically has two ways to keep your result:
1) "bringing the data back to driver (using collect () API. This works on both RDD and DATAFRAME). But keep in mind that This will" bringing whole dataset back to driver (one node), so if the dataset is very big, then you will have the memory pressure for that one node.
2) Saving the result the dataset into a distributed storage. This is a normal way will case. You can save your result into HDFS, S3, Cassandra, Hbase etc.
It looks like your originally code is trying to do in RDD API, so I demo in RDD with API but my RDD API is more powerful, but It misses the catalyst optimization, so its performance is not as good as DataFrame API will cases.
It looks like your originally code is trying to dedup of the data (Since you are using the MAP), but I have to warn you that It is dangerous to do what you tried to do. Keep in mind that the Spark in the or any distribution framework, the ORDER is never promised, unless you sort the data first, but It is a very expensive operation).
For example, if your text data is liking:
1, value1
2, value2
3, value3
1, valueNew
There is not promise that the last value "1, valueNew" will replace "1, value1", as they could be read by the company to the machine at totally company's time, so "1, valueNew" could read on the machine before 2 "1, value1" read on machine accounts for machine1, then using "valueNew" to replace "value1" is never good idea, unless your data from one more field to difference the order, like the following:
1, value1, 1
2, value2, 2
3, value3, 3
1, 4 valueNew,
So we can use the 3 rd column to tell us which should replace which, or use "offset" bytes from the file as the ordering the column too.
Anyway, the following example show you how to group them together and using "collect" "bringing them back to the driver
Scala> Spark. Version
Res2: String=2.1.0
Scala> Val textFile=sc. MakeRDD (Array (" 1, value1 ", "2, value2", "3, value3", "1, valueNew"))
TextFile, org. Apache. Spark. RDD. RDD [String]=ParallelCollectionRDD [0] at makeRDD ats & lt; Console> : 24
Scala> Val keyvalue=https://bbs.csdn.net/topics/textFile.map (s=> (s.s plit (", ") (0), s.s plit (", ") (1)))
Keyvalue: org. Apache. Spark. RDD. RDD [(String, String)]=MapPartitionsRDD [1] at the map at & lt; Console> 26:
Scala> Keyvalue. GroupByKey. Collect. Foreach (println)
(2, CompactBuffer (value2))
(3, CompactBuffer (value3))
(1, CompactBuffer (value1, valueNew))
nullnullnullnullnullnullnullnullnullnullnullnullnullnullnullnullnullnullnull