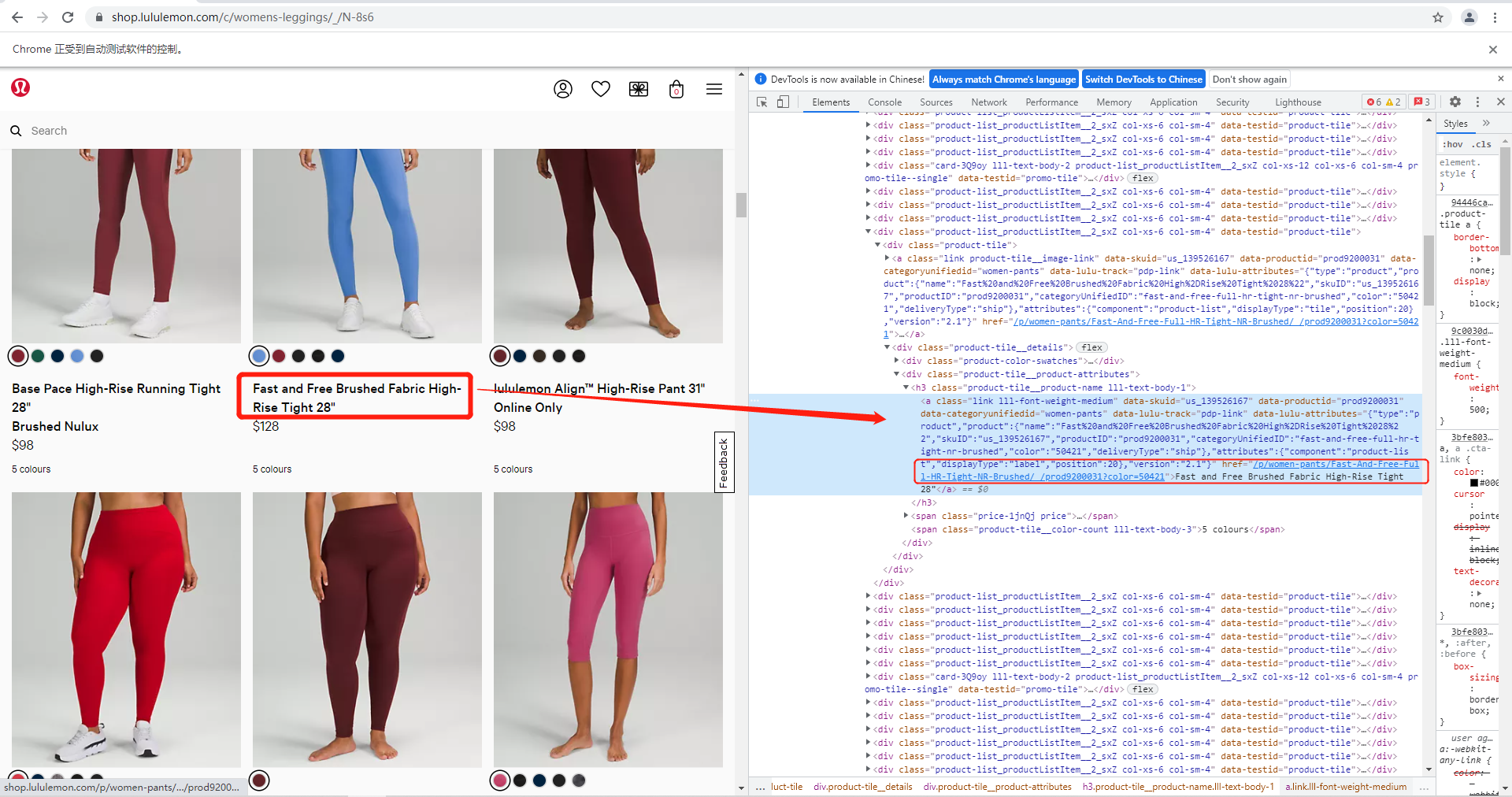
I'm practicing web scraping using Selenium and trying to scrape all the product links from Lululemon->Woman's main page. But I found that when I tried to use XPath to locate product URLs and then loop through the lists, the different part of each XPath for each product is in the middle, which suggests I cannot do as I expected.
For example, the Xpath of each product is :
/html/body/div[1]/div/main/div/section/div/div[3]/div[2]/div[2]/div/div[133]/div/div/div[2]/h3/a
/html/body/div[1]/div/main/div/section/div/div[3]/div[2]/div[2]/div/div[134]/div/div/div[2]/h3/a
/html/body/div[1]/div/main/div/section/div/div[3]/div[2]/div[2]/div/div[1]/div/div/div[2]/h3/a
See, the difference of each XPath lies in 133, 134, and 1, which represent the #id of products on this page
So how can I create a full list of information of all products (if XPath works) which allows me to loop through it to get every single product's list? Can anyone help me? I pasted my current code and attached the screenshot for reference. Thank you so much!
#this is how I got the web page
driver_path = 'D:/Python/Selenium/chromedriver'
url = "https://shop.lululemon.com/c/womens-leggings/_/N-8s6"
max_pass = 5
#get each product's url
option1 = webdriver.ChromeOptions()
option1.add_experimental_option('detach',True)
driver = webdriver.Chrome(chrome_options=option1,executable_path=driver_path)
driver.get(url)
sleep(2)
for i in range(max_pass):
sleep(3)
try:
driver.find_element_by_xpath('/html/body/div[1]/div/main/div/section/div/div[4]/div/button/span').click()
except:
pass
try:
driver.find_element_by_xpath('/html/body/div[1]/div/main/div/section/div/div[2]/div/button/span').click()
except:
pass
sleep(3)
driver.execute_script("window.scrollTo(0,document.body.scrollHeight);")
#the next step should be to find the pattern of where each URL is located (this should be a list), then I need to loop through the list to get "href" for every single product
#By the way, I have also tried to use class name "link lll-font-weight-medium" to locate, but I don't know why python says "Message: chrome not reachable (Session info: chrome=95.0.4638.69)"
[p.get_attribute('href') for p in driver.find_elements_by_class_name('link lll-font-weight-medium')] #this doesn't work
CodePudding user response:
To print the href attributes you need to induce WebDriverWait for the visibility_of_all_elements_located() and you can use either of the following Locator Strategies:
Using CSS_SELECTOR:
driver.get("https://shop.lululemon.com/c/womens-leggings/_/N-8s6") print([my_elem.get_attribute("href") for my_elem in WebDriverWait(driver, 20).until(EC.visibility_of_all_elements_located((By.CSS_SELECTOR, "h3.product-tile__product-name > a")))])Using XPATH:
driver.get("https://shop.lululemon.com/c/womens-leggings/_/N-8s6") print([my_elem.get_attribute("href") for my_elem in WebDriverWait(driver, 20).until(EC.visibility_of_all_elements_located((By.XPATH, "//h3[contains(@class, 'product-tile__product-name')]/a")))])Console Output:
['https://shop.lululemon.com/p/womens-leggings/Invigorate-HR-Tight-25/_/prod9750552?color=52445', 'https://shop.lululemon.com/p/womens-leggings/Wunder-Train-HR-Tight-25/_/prod9750562?color=47184', 'https://shop.lululemon.com/p/womens-leggings/Instill-High-Rise-Tight-25/_/prod10641675?color=30210', 'https://shop.lululemon.com/p/womens-leggings/Base-Pace-High-Rise-Tight-25/_/prod10641591?color=51039', 'https://shop.lululemon.com/p/womens-leggings/Align-Crop-21-Shine/_/prod10850236?color=51756', 'https://shop.lululemon.com/p/women-pants/Fast-And-Free-Tight-II-NR/_/prod8960003?color=28948', 'https://shop.lululemon.com/p/women-pants/Align-Pant-Full-Length-28/_/prod8780551?color=46741', 'https://shop.lululemon.com/p/women-pants/Align-Pant-2/_/prod2020012?color=26950', 'https://shop.lululemon.com/p/women-pants/Align-Pant-Super-Hi-Rise-28/_/prod9200552?color=26083']Note : You have to add the following imports :
from selenium.webdriver.support.ui import WebDriverWait from selenium.webdriver.common.by import By from selenium.webdriver.support import expected_conditions as EC
CodePudding user response:
Getting all links of the displayed products you can go with xpath but in my opinion css selectors are quiet more comfortable:
for a in driver.find_elements(By.CSS_SELECTOR, '[data-testid="product-list"] h3 a'):
print(a.get_attribute('href'))
Instead of printing in the iteration you can also append them to a list or process the single product page directly.
Example (selenium 4)
...
driver.get(url)
last_height = driver.execute_script("return document.body.scrollHeight")
while True:
driver.execute_script("window.scrollTo(0, document.body.scrollHeight);")
time.sleep(0.5)
new_height = driver.execute_script("return document.body.scrollHeight")
if new_height == last_height:
break
last_height = new_height
for a in driver.find_elements(By.CSS_SELECTOR, '[data-testid="product-list"] h3 a'):
print(a.get_attribute('href'))