I have two data frames: one (multiindex) of size (1113, 7897) containing values for different country and sectors in columns and different IDs in the row, example:
F_Frame:
AT BE ...
Food Energy Food Energy ...
ID1
ID2
...
In another dataframe (CC_LO) I have factor-values with corresponding country and IDs that I would like to match with the former dataframe (F_frame), so that I multiply values in F_frame with factorvalues on CC_LO if they match by country and ID. If they do not match, I put a zero.
The code I have so far, seems to work, but it runs very slowly. Is there a smarter way to match the tables based on the index/header names? (The code loops over 49 countries and multiply by the same factor for every 163 sector within the country)
LO_impacts = pd.DataFrame(np.zeros((1113,7987)))
for i in range(0, len(F_frame)):
for j in range(0, 49):
for k in range(0, len(CF_LO)):
if (F_frame.index.get_level_values(1)[i] == CF_LO.iloc[k,1] and
F_frame.columns.get_level_values(0)[j*163] == CF_LO.iloc[k,2]):
LO_impacts.iloc[i,(j*163):((j 1)*163)] = F_frame.iloc[i,(j*163):((j 1)*163)] * CF_LO.iloc[k,4]
else:
LO_impacts.iloc[i,(j*163):((j 1)*163)] == 0
CodePudding user response:
i have made two dataframes, then i setted a new index for the second dataFrame as below:
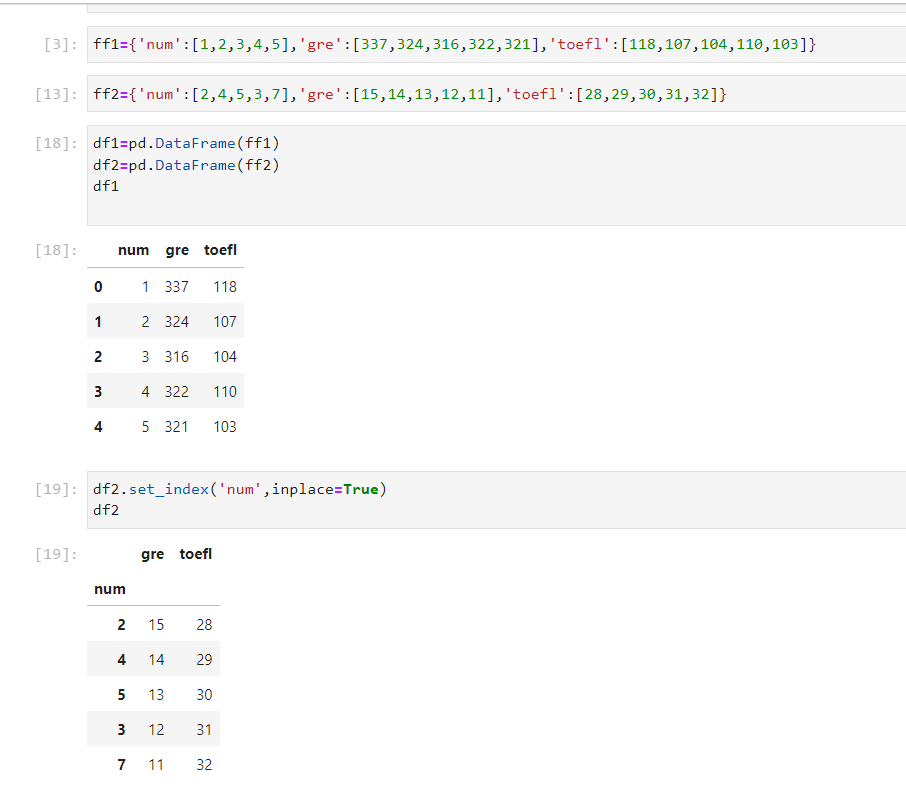
then i have used the function assign() to create a new column for df2:
df2=df2.assign(gre_multiply=lambda x: x.gre*df1.gre)
don't forget to make df2=, i forgot it in the picture.
and i have got the following dataFrame:
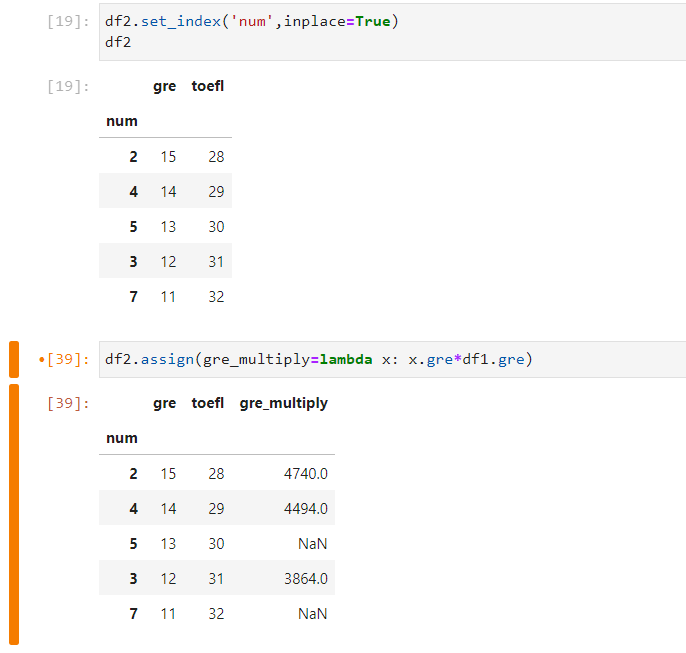
of course it look at index you can check using a calculator, it returns values as float, it is easy now to convert to int later df2.gre_multiply.astype(int)
but before that you need to fillna because if the indexes of the two dataframes don't match it will return Nan
df2.gre_multiply=df2.gre_multiply.fillna(0).astype(int)
CodePudding user response:
Thank you for the answer akram! What if I have multiple rows with the same ID? In my case, I would like to multiply all the rows of the same ID (e.g. S1) with the one value from the other dataframe that matches the same ID. Similar to this:
AT AT DK ....
ID
S1 2.0 4.3 5.5 ....
S1 1.1 5.7 6.8 ...
S2 6.7 8.6 9.0 ...
So for the all values matching ID = S1 and country = AT, I will multiply by 1 in the other dataframe:
ID Country Value
S1 AT *1*
S1 DK 0.8
S2 AT 0.9
S2 DK 0.6
...
So that in a new dataframe, I will have:
AT AT DK ....
ID
S1 2.0*1 4.3*1 5.5*0.8 ....
S1 1.1*1 5.7*1 6.8*0.8 ...
S2 6.7*0.9 8.60.9 9.0*0.6 ...
Hope it's clear.