I'm new to working with LSTMs and I'm stuggling to understand them even intuitively.
I'm using them for a Regression problem, I'm having about 6000 datasets of ~450 timesteps each and every timestep has 11 features. The target values are 2d ~ [a,b] and they are the same for a single dataset. After training I want to provide the timesteps and predict the 2d y value.
Example: dataset (1 out of 6000) has ~450 different timesteps of type x = [1,2,3,4,5,6,7,8,9,10,11] and a target value y = [1,2]
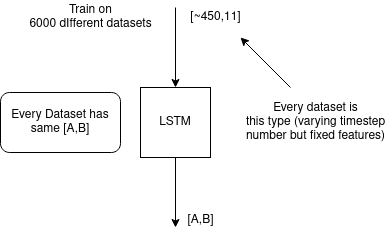
The problems I'm having currently is understanding what exactly LSTM learns in terms of correlation between inputs, what data do I feed exactly and in what order if I'm dealing with multiple datasets? I'm confused of the term batch_size and what happens with the term seq_length if I have a varying sequences... Do I pass the whole 450 timesteps as sequences?
What I do now is merging all the data in a csv file and passing them to the model. I couldn't run it because of memory problems so I reduced it to 5000 timesteps,
below is the LSTM class I use
''' class LSTM(nn.Module):
def __init__(self, num_classes, input_size, hidden_size, num_layers):
super(LSTM, self).__init__()
self.num_classes = num_classes
self.num_layers = num_layers
self.input_size = input_size
self.hidden_size = hidden_size
self.seq_length = seq_length
self.lstm = nn.LSTM(input_size=input_size, hidden_size=hidden_size,
num_layers=num_layers, batch_first=True)
self.fc = nn.Linear(hidden_size, num_classes)
def forward(self, x):
h_0 = Variable(torch.zeros(
self.num_layers, x.size(0), self.hidden_size))
c_0 = Variable(torch.zeros(
self.num_layers, x.size(0), self.hidden_size))
# Propagate input through LSTM
ula, (h_out, _) = self.lstm(x, (h_0, c_0))
h_out = h_out.view(-1, self.hidden_size)
out = self.fc(h_out)
return out, h_out
'''
I don't really need technical answers.. I would really like if somebody could clarify what is going on in this scenario and how I should approach it... I've searched dozens of posts online but it seems I just don't get it or it is not exactly my case.
CodePudding user response:
I will try to explain this in a way that also explains the vocabulary.
LSTMs are often used for sequential data, for example a time series, where you have data points x_t for multiple time steps t=t0...tN. Here, N would be the sequence length (=seq_length?). Now that means for D-dimensional data, one "dataset" or more precisely, one sequence has the shape N x D.
Let us for now assume that N is equal for all sequences. That means, if you have B sequences, you can stack them into a B x N x D tensor - this would correspond to the actual dataset, which is basically all data that you use. Here, B is your batch axis, basically just meaning the axis where you stack independent sequences. If you choose to train on all data at the same time, you could just pass your complete B x N x D dataset to the model. Then, your batch size would be B. (a Note below)
Now if the sequence length is not equal, there are multiple things you could do. First, you should ask yourself if you want to train on the full sequences. Is it necessary to read the full N steps to get an estimate of the result, or could it be enough to only look at n < N steps? If that is the case, you can sample b (your new batch size, which you can define how you like) sequences of length n, where n < N for all sequences.
If parts of the sequence are not sufficient to estimate the result, it gets more complicated. Then I would suggest to feed the full sequences individually and just train on single sequences. This basically means the batchsize b=1, since you can not stack the sequences as their length differs pairwise. Here, you will feed your model with a b x n x D tensor.
I'm not sure if any of this is "standard procedure", but this is how I would address this.
NOTE: Training on the full dataset is usually not a good practice. Typically, you want to sample b < B random batches from your dataset, which randomizes your training.
CodePudding user response:
LSTMs process sequential data by identifying sequential patterns (can also be thought of as time-based patterns if that is the axis) in order to provide either sequential outputs (a set of outputs for each sequence position, NOT your case), or an output per sequence (your case). This information is passed through the network through the memory backbone (also called a constant error carousel) which can pass through the entire sequence , even bidirectionally (although this is separated between forward and backward passes).
PyTorch explains how it wants your data to be handled:
input: tensor of shape is (L,N,Hin) when batch_first=False or (N,L,Hin) is (N,L,H in) when batch_first=True containing the features of the input sequence. The input can also be a packed variable length sequence. See torch.nn.utils.rnn.pack_padded_sequence() or torch.nn.utils.rnn.pack_sequence() for details.
So your data should be a 3D tensor when being input into an RNN model, although note that variable length sequences are catered for in the rnn.pack_sequence (or pack_padded_sequence) functionality of PyTorch. These will account for the variable lengths so that your data is not affected by zero padding, which wouldn't be good when you shuffle your batches around or are in inference for a single sequences.
Finally, batching data is a way to process multiple datapoints (in this case, sequences) at once in order to speed up training by averaging multiple samples at once and back propagating the loss jointly, while taking the same amount of time to do so (roughly) as a single datapoint. Sequences are tricky in this regard because it is very common to not have them be the same length, but normally this is handled by zero-padding the sequences to the max length in the batch.