[root @ master spark - 2.0.1 - bin - hadoop2.7] #./sbin/start - all. Sh
Org. Apache. Spark. Deploy. Master. Master running as process 3530. Stop it first.
Slaver1: starting org. Apache. Spark. Deploy. Worker. The worker, logging to/usr/spark spark - 2.0.1 - bin - hadoop2.7/logs/spark - root - org. Apache. Spark. Deploy. Worker. The worker - 1 - slaver1. Out
Slaver2: starting org. Apache. Spark. Deploy. Worker. The worker, logging to/usr/spark spark - 2.0.1 - bin - hadoop2.7/logs/spark - root - org. Apache. Spark. Deploy. Worker. The worker - 1 - slaver2. Out
Slaver1: failed to launch org. Apache. Spark. Deploy. Worker. The worker:
Slaver1: at org. Apache. Spark. Deploy. Worker. The worker $. The main (693) the worker. The scala:
Slaver1: at org. Apache. Spark. Deploy. Worker. The worker. The main (worker. Scala)
Slaver1: full log in/usr/spark spark - 2.0.1 - bin - hadoop2.7/logs/spark - root - org. Apache. Spark. Deploy. Worker. The worker - 1 - slaver1. Out
Slaver2: failed to launch org. Apache. Spark. Deploy. Worker. The worker:
Slaver2: at org. Apache. Spark. Deploy. Worker. The worker $. The main (693) the worker. The scala:
Slaver2: at org. Apache. Spark. Deploy. Worker. The worker. The main (worker. Scala)
Slaver2: full log in/usr/spark spark - 2.0.1 - bin - hadoop2.7/logs/spark - root - org. Apache. Spark. Deploy. Worker. The worker - 1 - slaver2. Out
My spark - env. Sh is as follows:
Export JAVA_HOME=/usr/Java/jdk1.8.0 _101
Export SCALA_HOME=/usr/scala scala - 2.11.8
Export SPARK_MASTER_IP=master
Export SPARK_WORKER_MEMORY=0.5 g
Export HADOOP_HOME=/usr/hadoop/hadoop - 2.7.3
Export HADOOP_CONF_DIR=${HADOOP_HOME}/etc/hadoop
Export SPARK_WORKER_CORES=1
Export SPARK_MASTER_PORT=7077
Export SPARK_LOCAL_DIRS=/usr/spark/spark - 2.0.1
# set ipython start
PYSPARK_DRIVER_PYTHON=ipython
When I started on Hadoop./sbin/start - all. Sh, each node can run normally,
But on the spark started./sbin/start - all. Sh, is called the above fault,
I three virtual machine memory is 2 g, the system is the red hat 5.
Start the Hadoop, 192.168.183.70:50070 pages of content is as follows:
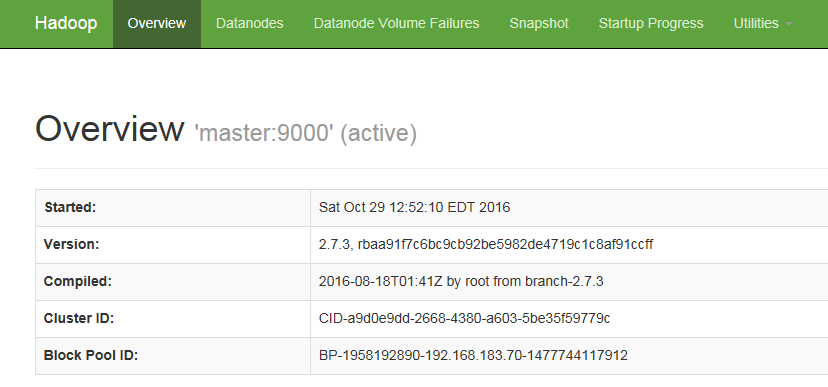
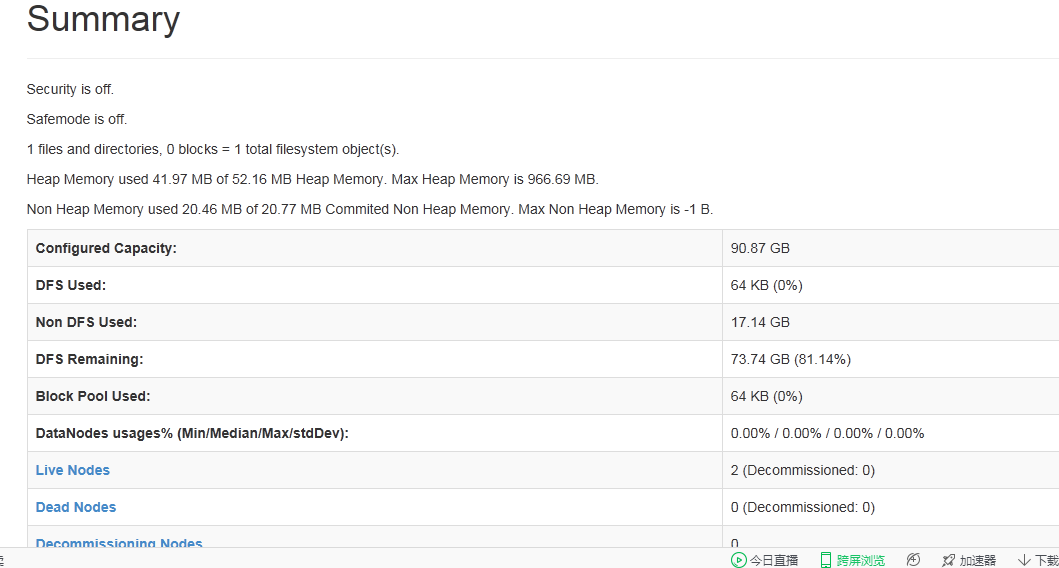
Strives for the great god teach, what to do,
CodePudding user response:
Slaver1: full log in/usr/spark spark - 2.0.1 - bin - hadoop2.7/logs/spark - root - org. Apache. Spark. Deploy. Worker. The worker - 1 - slaver1. OutYou won't know until you post a log of the worker come up specific issues
CodePudding user response:
3 the virtual machine, live node should be 3