I have data like this
df <- data.frame(var1 = c("A", "A", "B", "B", "C", "D", "E"), var2 = c(1, 2, 3, 4, 5, 5, 6 ))
# var1 var2
# 1 A 1
# 2 A 2
# 3 B 3
# 4 B 4
# 5 C 5
# 6 D 5
# 7 E 6
A is mapped to 1, 2
B is mapped to 3, 4
C and D are both mapped to 5 (and vice versa: 5 is mapped to C and D)
E is uniquely mapped to 6 and 6 is uniquely mapped to E
I would like filter the dataset so that only
var1 var2
7 E 6
is returned. base or tidyverse solution are welcomed.
I have tried
unique(df$var1, df$var2)
df[!duplicated(df),]
df %>% distinct(var1, var2)
but without the wanted result.
CodePudding user response:
Using igraph::components.
Represent data as graph and get connected components:
library(igraph)
g = graph_from_data_frame(df)
cmp = components(g)
Grab components where cluster size (csize) is 2. Output vertices as a two-column character matrix:
matrix(names(cmp$membership[cmp$membership %in% which(cmp$csize == 2)]),
ncol = 2, dimnames = list(NULL, names(df))) # wrap in as.data.frame if desired
# var1 var2
# [1,] "E" "6"
Alternatively, use names of relevant vertices to index original data frame:
v = names(cmp$membership[cmp$membership %in% which(cmp$csize == 2)])
df[df$var1 %in% v[1:(length(v)/2)], ]
# var1 var2
# 7 E 6
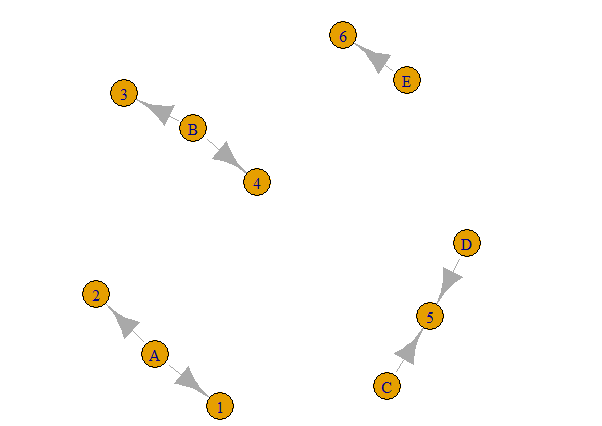
Visualize the connections:
plot(g)
CodePudding user response:
Using a custom function to determine if the mapping is unique you could achieve your desired result like so:
df <- data.frame(
var1 = c("A", "A", "B", "B", "C", "D", "E"),
var2 = c(1, 2, 3, 4, 5, 5, 6)
)
is_unique <- function(x, y) ave(as.numeric(factor(x)), y, FUN = function(x) length(unique(x)) == 1)
df[is_unique(df$var2, df$var1) & is_unique(df$var1, df$var2), ]
#> var1 var2
#> 7 E 6
CodePudding user response:
Another igraph option
decompose(graph_from_data_frame(df)) %>%
subset(sapply(., vcount) == 2) %>%
sapply(function(g) names(V(g)))
which gives
[,1]
[1,] "E"
[2,] "6"
CodePudding user response:
A base R solution:
df[!(duplicated(df$var1) | duplicated(df$var1, fromLast = TRUE) |
duplicated(df$var2) | duplicated(df$var2, fromLast = TRUE)), ]
var1 var2
7 E 6