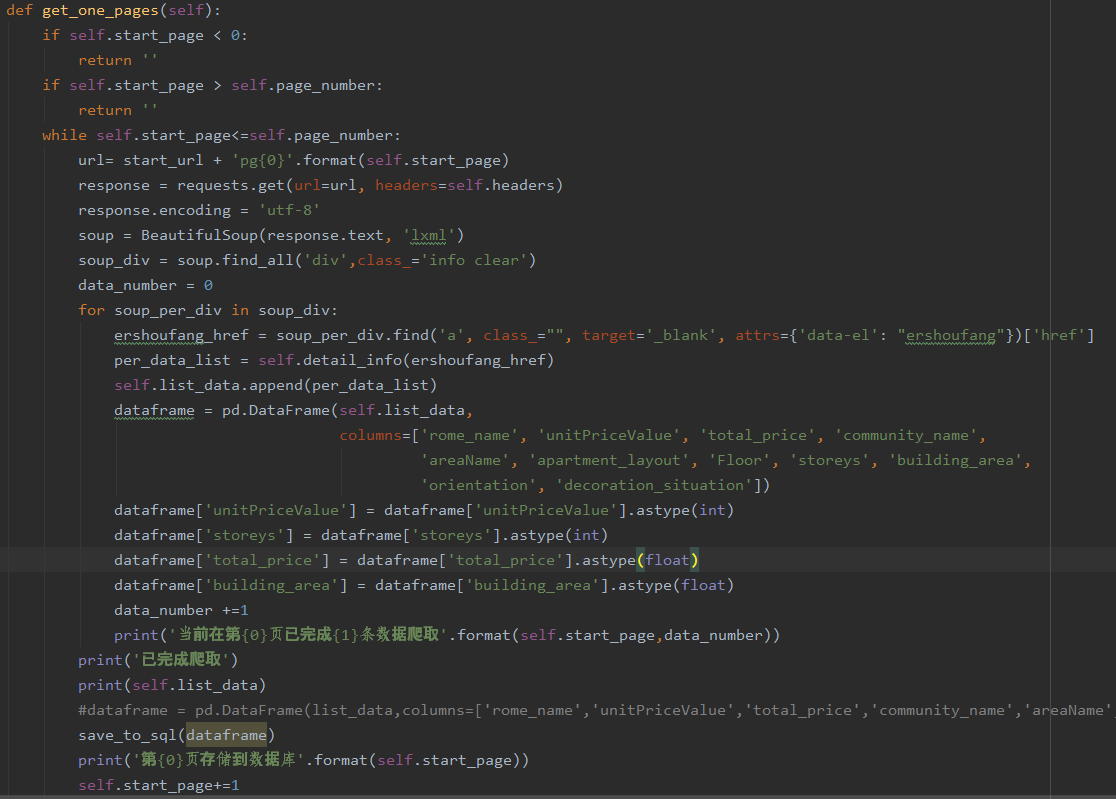
Def get_one_pages (self) :
If self. Start_page & lt; 0:
Return '
If self. Start_page & gt; Self. Page_number:
Return '
While the self. Start_page & lt;=self. Page_number:
Url=start_url + pg '{0}'. The format (self. Start_page)
The response=requests. Get (url=url, headers=self. Headers)
The response. The encoding="utf-8"
Soup=BeautifulSoup (the response text, 'LXML')
Soup_div=soup. Find_all (' div ', class_='info clear')
Data_number=0
For soup_per_div soup_div in:
Ershoufang_href=https://bbs.csdn.net/topics/soup_per_div.find (' a ', class_="" target=" _blank ", attrs={' data - el: "ershoufang"}) [' href ']
Per_data_list=self. Detail_info (ershoufang_href)
Self. List_data. Append (per_data_list)
Dataframe=pd. Dataframe (self list_data,
The columns=[' rome_name ', 'unitPriceValue', 'total_price', 'community_name,
'areaName', 'apartment_layout', 'Floor', 'storeys',' building_area '
'orientation' and 'decoration_situation'])
Dataframe [' unitPriceValue]=dataframe [' unitPriceValue] astype (int)
Dataframe [' storeys']=dataframe [' storeys'] astype (int)
Dataframe [' total_price]=dataframe [' total_price] astype (float)
Dataframe [' building_area]=dataframe [' building_area] astype (float)
Data_number +=1
Print (' current in the first article completed {1} {0} page data crawl '. The format (self. Start_page data_number))
Print (' completed crawl)
Print (self. List_data)
Save_to_sql (dataframe)
Print (' {0} first page stored in the database. The format (self. Start_page))
Self. Start_page +=1
CodePudding user response:
 words not too clear to see the pictures, small white base is not very good, thank you
words not too clear to see the pictures, small white base is not very good, thank youCodePudding user response:
After each cycle of the self. The datalist to empty, solved the problem,,