Home > other > The spark deserialization sometimes time is too long
The spark deserialization sometimes time is too long
Time:09-24
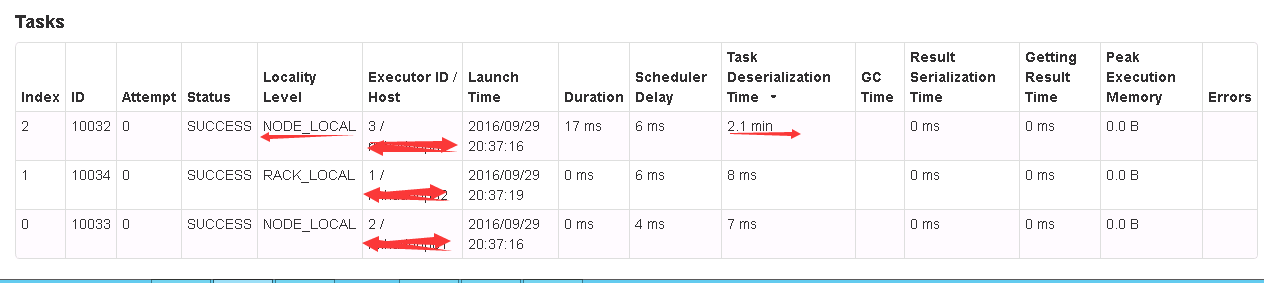
In the spark in the cluster, the server's configuration is differ, the server configuration is a bit poor sometimes mission deserialized to 2 minutes, using serialization is org. Apache. Spark. Serializer. KryoSerializer, what reason is this excuse me?
The server configuration: 32 core/126 g Operation mode: run on yarn Resource use: less than one 5 of the
CodePudding user response:
CodePudding user response:
Just saw an article that may help you here
CodePudding user response:
First of all thank you for your reply, upstairs I am already using Kryo are faced with the problem, and also to have some kind of registered, however, about 200 times the execution of the stag there will always be one or two stage deserialization time to a minimum of 2 minutes (normal processing time is about 4 seconds), and processing the data is not much,