I have a large amount of JSON data and I want to perform some tasks. so I choose pandas for this.
I have a nested json like this :
json_data = [
{
"item": "Item1",
"lowestPrice": {
"price": 11.00,
"currency": "EUR",
},
},
{
"item": "Item2",
"lowestPrice": {
"price": 12.00,
"currency": "EUR",
}
},
{
"item": "Item3",
"lowestPrice": {
"price": 13.00,
"currency": "EUR",
}
}
]
and i used json_normalize() to normalize nested json like:
df = pd.json_normalize(json_data, max_level=2)
item lowestPrice.price lowestPrice.currency
0 Item1 11.0 EUR
1 Item2 12.0 EUR
2 Item3 13.0 EUR
#do something
now I need data back as a nested JSON or dict like:
json_data = [
{
"item": "Item1",
"lowestPrice": {
"price": 11.00,
"currency": "EUR",
},
"annotatePrice": 15.00
},
{
"item": "Item2",
"lowestPrice": {
"price": 12.00,
"currency": "EUR",
},
"annotatePrice": 15.00
},
{
"item": "Item3",
"lowestPrice": {
"price": 13.00,
"currency": "EUR",
},
"annotatePrice": 15.00
}
]
CodePudding user response:
First, I added the column annotatePrice to the dataframe. Then constructed the inner dictionary for lowestPrice, followed by the outer dictionary. I sourced my solution from this 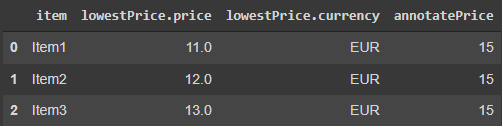
Conversion code:
df = pd.json_normalize(json_data, max_level=2)
df['annotatePrice'] = 15
json_data = (df.groupby(['item', 'annotatePrice'])
.apply(lambda x: x[['lowestPrice.price', 'lowestPrice.currency']].rename(columns={"lowestPrice.price":'price', "lowestPrice.currency":'currency'}).to_dict('records')[0])
.reset_index()
.rename(columns={0:'lowestPrice'})
.to_dict(orient='records'))
json_data
Output:
[
{
'annotatePrice': 15,
'item': 'Item1',
'lowestPrice': {
'currency': 'EUR',
'price': 11.0
}
},
{
'annotatePrice': 15,
'item': 'Item2',
'lowestPrice': {
'currency': 'EUR',
'price': 12.0
}
},
{
'annotatePrice': 15,
'item': 'Item3',
'lowestPrice': {
'currency': 'EUR',
'price': 13.0
}
}
]