I am trying to download numerous annual accounts in pdf format from an open-source database in Belgium.
I want to use selenium to do that.
However, the dynamic content is endlessly loading when a search term is entered.
HAVE:
WANT:
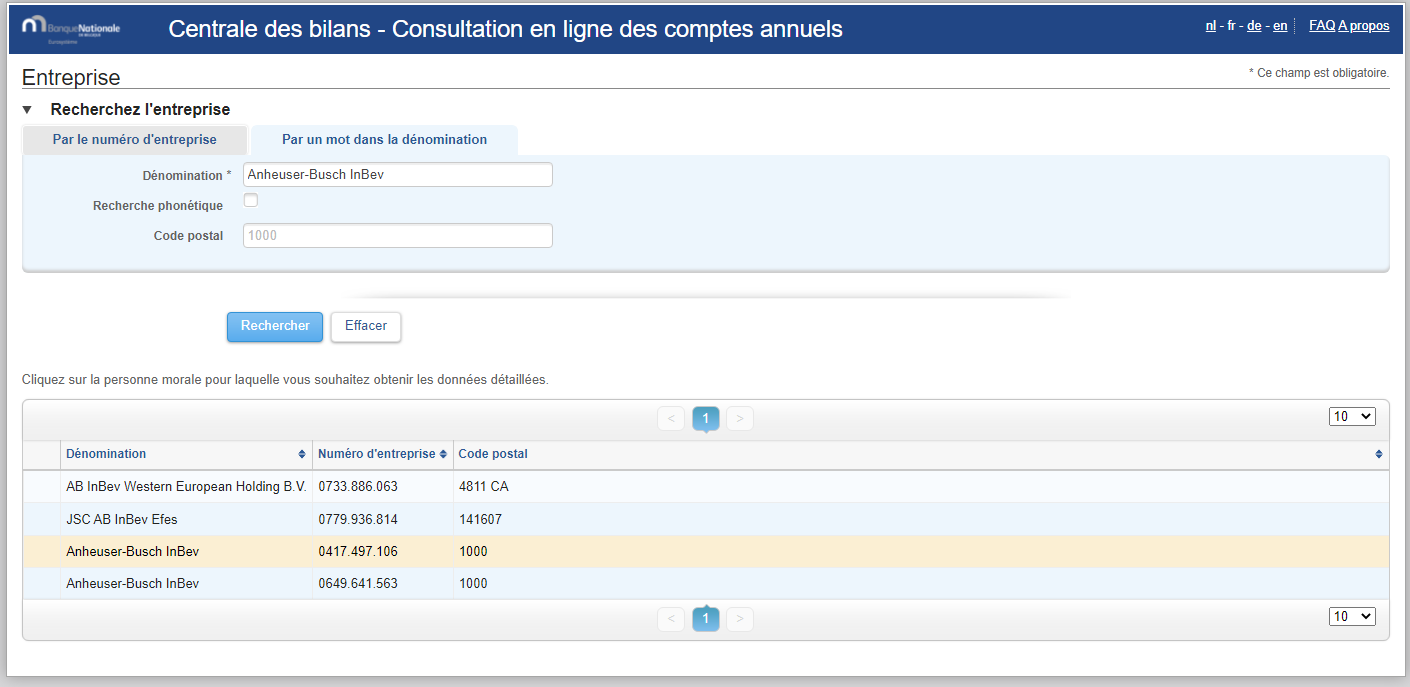
Everything works fine when I do the same steps manually. I tried to insert some timeouts here and there but it does not solve the issue.
Here is my code:
from selenium import webdriver
from selenium.webdriver.support import expected_conditions as ec
from selenium.webdriver.support.ui import WebDriverWait
from selenium.webdriver.common.by import By
from selenium.webdriver.common.action_chains import ActionChains
from selenium.webdriver.common.keys import Keys
import time
PATH = "C:\Program Files (x86)\chromedriver.exe"
driver = webdriver.Chrome(PATH)
actions = ActionChains(driver)
driver.get("http://cri.nbb.be/bc9/web/catalog?lang=F")
search_by_name = WebDriverWait(driver, 5, 0.25).until(ec.element_to_be_clickable([By.XPATH , '/html/body/div[2]/div[1]/div/div/div/div/div[1]/div/div/form[1]/div/div[2]/div[1]/div/div/div[1]/ul/li[2]']))
actions.move_to_element(search_by_name).click().perform()
search_box = driver.find_element_by_xpath('/html/body/div[2]/div[1]/div/div/div/div/div[1]/div/div/form[1]/div/div[2]/div[1]/div/div/div[2]/div[2]/div[1]/div/div[3]/div/input')
search_box.send_keys("Anheuser-Busch InBev")
search_box.send_keys(Keys.ENTER)
CodePudding user response:
I agree with @PiotrM. You must use API if given any. Having said that, you are using absolute xpaths, which may get clumsy. Here is what I have refactored, and it works until what you've shown in the query.
driver.get("http://cri.nbb.be/bc9/web/catalog?lang=F")
WebDriverWait(driver, 20).until(EC.element_to_be_clickable((By.XPATH, "//div[@class='navTab']//li[contains(@class,'last')]"))).click()
WebDriverWait(driver, 10).until(EC.visibility_of_element_located((By.XPATH, "//input[@placeholder='Banque']"))).send_keys("Anheuser-Busch InBev")
driver.find_element(By.XPATH, "//div[@id='page_searchForm:actions']//button").click()