I have a dataset with columns user_id, type and purchase:
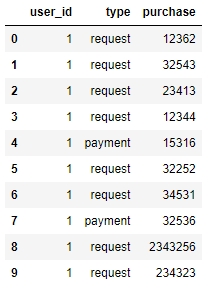
I want to calculate maximum sum previous payment.
Example tables:
| user_id | type | purchase | prev_payment |
|---|---|---|---|
| 1 | request | 12362 | NA |
| 1 | request | 32543 | NA |
| 1 | request | 23413 | NA |
| 1 | request | 12344 | NA |
| 1 | payment | 15316 | NA |
| 1 | request | 32252 | 15316 |
| 1 | request | 34531 | 15316 |
| 1 | payment | 32536 | 15316 |
| 1 | request | 2343256 | 32536 |
| 1 | request | 234323 | 32536 |
data = [[1, 'request', 12362], [1, 'request', 32543], [1, 'request', 23413], [1, 'request', 12344], [1, 'payment', 15316],
[1, 'request', 32252], [1, 'request', 34531], [1, 'payment', 32536], [1, 'request', 2343256], [1, 'request', 234323]]
df = pd.DataFrame(data, columns = ['user_id', 'type', 'purchase'])
CodePudding user response:
You can mask your data to keep only the "payment" rows, then shift and ffill:
df['prev_payment'] = df['purchase'].where(df['type'].eq('payment')).shift().ffill()
output:
type purchase prev_payment
0 request 12362 NaN
1 request 32543 NaN
2 request 23413 NaN
3 request 12344 NaN
4 payment 15316 NaN
5 request 32252 15316.0
6 request 34531 15316.0
7 payment 32536 15316.0
8 request 2343256 32536.0
9 request 234323 32536.0
per group:
df['prev_payment'] = (df['purchase']
.where(df['type'].eq('payment'))
.groupby(df['user_id'])
.apply(lambda s: s.shift().ffill())
)