Business code would only write four years of development, the distributed high concurrency also can't be a programmer? ->>
"Recommendation system practice" 2.4 gave different k values corresponding to the recall rate, accuracy, etc., but I calculate and book,
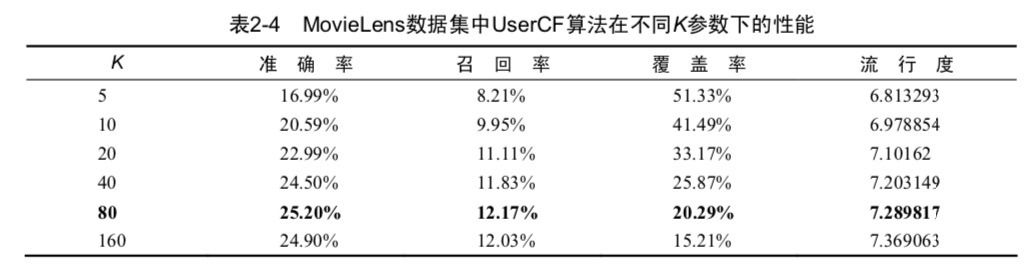
With the data set is: https://grouplens.org/datasets/movielens/1m/, according to the description in the book of 6000 users, 4000 films, a score of 100 w,
CodePudding user response:
The author used the 1 million data is divided into eight points, seven of them as the training set, 1 as the test set dataset partition ratio is different, the resulting data will have some different,When your test set ratio is too small, the result may be on the low side,
Another result can't be exactly the same, or is because every piece of data into the test set or enter the training set is random, identical but feel a little can't understand,