I have a dataframe like this:
department review projects salary satisfaction bonus avg_hrs_month left
0 operations 0.577569 3 low 0.626759 0 180.866070 0
1 operations 0.751900 3 medium 0.443679 0 182.708149 0
2 support 0.722548 3 medium 0.446823 0 184.416084 0
3 logistics 0.675158 4 high 0.440139 0 188.707545 0
4 sales 0.676203 3 high 0.577607 1 179.821083 0
I want to try ColumnTransformer() and return a transformed dataframe.
ord_features = ["salary"]
ordinal_transformer = OrdinalEncoder()
cat_features = ["department"]
categorical_transformer = OneHotEncoder(handle_unknown="ignore")
ct = ColumnTransformer(
transformers=[
("ord", ordinal_transformer, ord_features),
("cat", categorical_transformer, cat_features ),
]
)
df_new = ct.fit_transform(df)
df_new
which gives me a 'sparse matrix of type '<class 'numpy.float64'>'
if I use pd.DataFrame(ct.fit_transform(df)) then I'm getting a single column:
0
0 (0, 0)\t1.0\n (0, 7)\t1.0
1 (0, 0)\t2.0\n (0, 7)\t1.0
2 (0, 0)\t2.0\n (0, 10)\t1.0
3 (0, 5)\t1.0
4 (0, 9)\t1.0
however, I was expecting to see the transformed dataframe like this?
review projects salary satisfaction bonus avg_hrs_month operations support ...
0 0.577569 3 1 0.626759 0 180.866070 1 0
1 0.751900 3 2 0.443679 0 182.708149 1 0
2 0.722548 3 2 0.446823 0 184.416084 0 1
3 0.675158 4 3 0.440139 0 188.707545 0 0
4 0.676203 3 3 0.577607 1 179.821083 0 0
Is it possible with ColumnTransformer()?
CodePudding user response:
As quickly sketched in the comment there are a couple of considerations to be done on your example:
method
.fit_transform()generally returns either a sparse matrix or a numpy array. Returning a sparse matrix serves the purpose of saving memory; think to the example where you one-hot-encode a categorical attribute with many categories. You'll end up having a matrix with many columns and a single non-zero entry per row; with a sparse matrix you can store the location of the non-zero element only. In these situation you can call.toarray()on the output of.fit_transform()to get a numpy array back to be passed to thepd.DataFrameconstructor.Actually, on a five-rows dataset similar to the one you provided
df = pd.DataFrame({ 'department': ['operations', 'operations', 'support', 'logistics', 'sales'], 'review': [0.577569, 0.751900, 0.722548, 0.675158, 0.676203], 'projects': [3, 3, 3, 4, 3], 'salary': ['low', 'medium', 'medium', 'low', 'high'], 'satisfaction': [0.626759, 0.751900, 0.722548, 0.675158, 0.676203], 'bonus': [0, 0, 0, 0, 1], 'avg_hrs_month': [180.866070, 182.708149, 184.416084, 188.707545, 179.821083], 'left': [0, 0, 1, 0, 0] }) ord_features = ["salary"] ordinal_transformer = OrdinalEncoder() cat_features = ["department"] categorical_transformer = OneHotEncoder(handle_unknown="ignore") ct = ColumnTransformer(transformers=[ ("ord", ordinal_transformer, ord_features), ("cat", categorical_transformer, cat_features), ])I can't reproduce your issue (namely, I directly obtain a numpy array), but basically
pd.DataFrame(ct.fit_transform(df).toarray())should work for your case. This is the output you would get: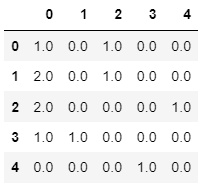
As you can see, with respect to your expected output, this only contains the transformed (ordinally encoded) salary column as first column and the transformed (one-hot-encoded) department column from the second to the last column. That's because, as you can see within the
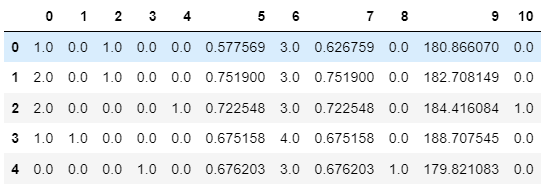
Again, as you can see also column order is not the one you would expect after the transformation. Long story short, that's because in a
ColumnTransformer
The order of the columns in the transformed feature matrix follows the order of how the columns are specified in the transformers list. Columns of the original feature matrix that are not specified are dropped from the resulting transformed feature matrix, unless specified in the passthrough keyword. Those columns specified with passthrough are added at the right to the output of the transformers.
I would aggest reading Preserve column order after applying sklearn.compose.ColumnTransformer at this proposal.
- Eventually, for what concerns column names you should probably apply a custom solution passing what you want directly to the
columnsparameter to be passed to thepd.DataFrameconstructor. Indeed,OrdinalEncoder(differently fromOneHotEncoder) does not provide a.get_feature_names_out()method that makes it generally easy to passcolumns=ct.get_feature_names_out()to thepd.DataFrameconstructor. See ColumnTransformer & Pipeline with OHE - Is the OHE encoded field retained or removed after ct is performed? for an example of its usage.