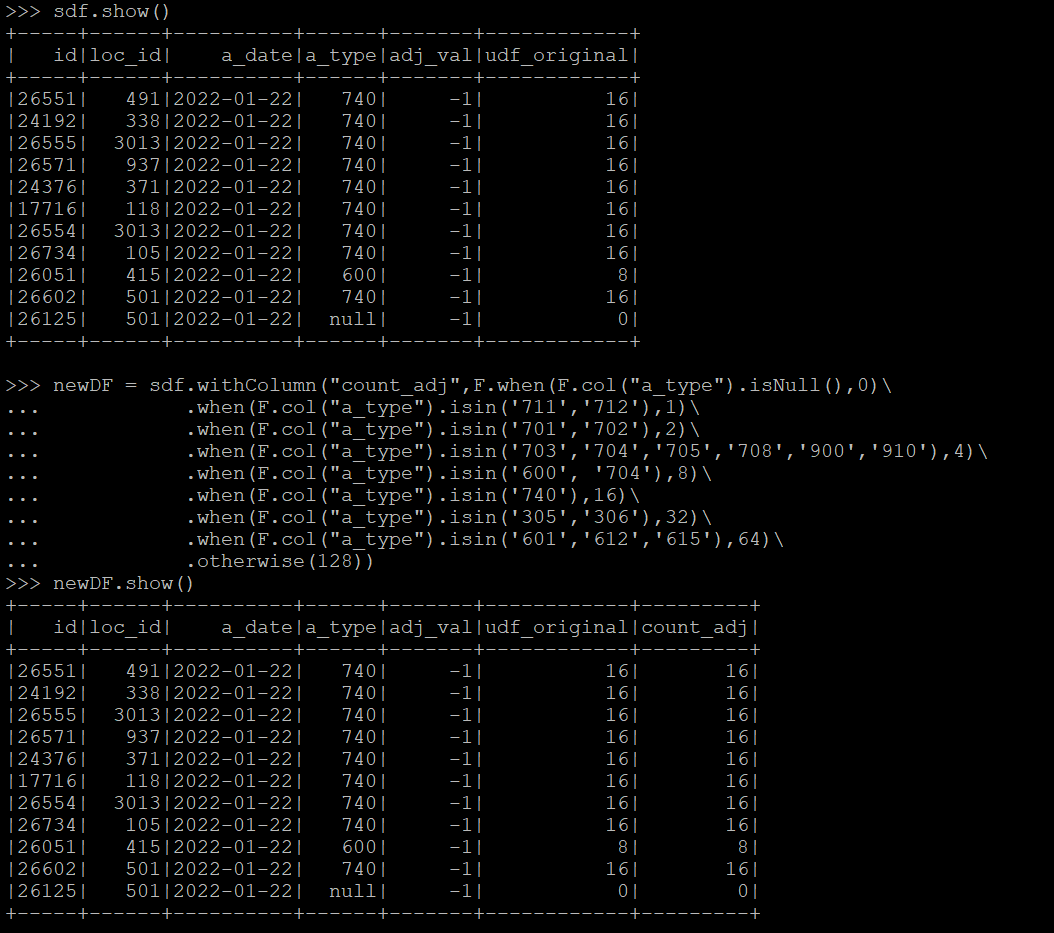
Pardon my ignorance, I am new to pyspark. I'm trying to improve a udf to create a new column count_adj based on values from another column a_type using a dictionary. How do I account for None / Null types in this process to create my new column. This is super easy in pandas (df['adj_count'] = df.a_type.map(count_map)) but struggling do this in pyspark.
Sample data / imports:
# all imports used -- not just for this portion of the script
from pyspark.sql import SparkSession, HiveContext, SQLContext
from pyspark import SparkConf
from pyspark import SparkContext
from pyspark import sql
import pyspark.sql.functions as F
import random
from pyspark.sql.functions import lit
from pyspark.sql.types import *
from pyspark.sql.functions import udf
from datetime import datetime
from datetime import date
from datetime import timedelta
from pyspark.sql import Window
from pyspark.sql.functions import broadcast
from pyspark.sql.functions import rank, row_number, max as max_, col
import sys
import os
spark = SparkSession.builder.appName('a_type_tests').getOrCreate()
# note: sample data has results from the original udf for comparison
dataDictionary = [
(26551, 491, '2022-01-22', '740', -1, 16),
(24192, 338, '2022-01-22', '740', -1, 16),
(26555, 3013, '2022-01-22', '740', -1, 16),
(26571, 937, '2022-01-22', '740', -1, 16),
(24376, 371, '2022-01-22', '740', -1, 16),
(17716, 118, '2022-01-22', '740', -1, 16),
(26554, 3013, '2022-01-22', '740', -1, 16),
(26734, 105, '2022-01-22', '740', -1, 16),
(26051, 415, '2022-01-22', '600', -1, 8),
(26602, 501, '2022-01-22', '740', -1, 16),
(26125, 501, '2022-01-22', None, -1, 0)
]
sdf = spark.createDataFrame(data=dataDictionary, schema = ['id', 'loc_id', 'a_date', 'a_type', 'adj_val', 'udf_original'])
sdf.printSchema()
sdf.show(truncate=False)
The original udf is similar to:
def count_adj(a_type):
if a_type is None:
return 0
elif a_type in ('703','704','705','708','900','910'):
return 4
elif a_type in ('701','702'):
return 2
elif a_type in ('711','712'):
return 1
elif a_type in ('600', '704'):
return 8
elif a_type in ('740'):
return 16
elif a_type in ('305','306'):
return 32
elif a_type in ('601','612','615'):
return 64
else:
return 128
I've created a dictionary to correspond to these values.
# remove 0:None type pairing because None is not iterable to invert dict
count_map = {1:['711','712'], \
2:['701','702'], \
4:['703','704','705','708','900','910'], \
8:['600', '704'], \
16:['740'], \
32:['305','306'], \
64:['601','612','615'], \
128: ['1600', '1601', '1602']
}
# invert dict
count_map = {c:key for key, vals in count_map.items() for c in vals}
# create None mapping manually
count_map[None] = 0
Searching SO I came across