Here is a simplified version of data I am working with:
a<-c("There are 5 programs", "2 - adult programs, 3- youth programs","25", " ","there are a number of programs","other agencies run our programs")
b<-c("four", "we don't collect this", "5 from us, more from others","","","")
c<-c(2,6,5,8,2,"")
df<-cbind.data.frame(a,b,c)
df$c<-as.numeric(df$c)
I want to keep both the text and numbers from the data b/c some of the text is important
expected output:
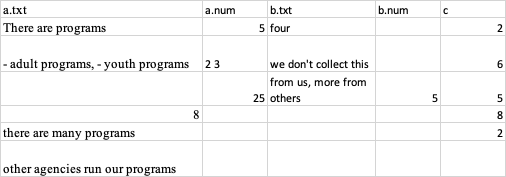
What I think makes sense is the following:
- id all columns that have text in them, perhaps in a list (because some columns are just numbers)
- subset columns from step 1 to a new dataframe lets call this df1
- delete the subsetted columns in df1 from df
- split all the columns in df1 into 2 columns, one that keeps the text and one that has the number.
- bind the new spit columns from df1 into the orginal df
What I am struggling with is steps 1-2 and 4. I am okay with the characters (e.g., - and ') being excluded or included. There is additional processing I have to do after (e.g., when there are multiple numbers in a column after splitting I will need to split and add these and also address the written numbers), but those are things I can do.
CodePudding user response:
Here is what I would do with my preferred tools.
library(data.table) # development version 1.14.3 used here
library(magrittr) # piping used to improve readability
num <- \(x) stringr::str_extract_all(x, "\\d ", simplify = TRUE) %>%
apply(1L, \(x) sum(as.integer(x), na.rm = TRUE))
txt <- \(x) stringr::str_remove_all(x, "\\d ") %>%
stringr::str_squish()
cbind(
setDT(df)[, lapply(.SD, \(x) data.table(txt = txt(x), num = num(x))),
.SDcols = is.character],
df[, .SD, .SDcols = !is.character]
)
which returns
a.txt a.num b.txt b.num c <char> <int> <char> <int> <num> 1: There are programs 5 four 0 2 2: - adult programs, - youth programs 5 we don't collect this 0 6 3: 25 from us, more from others 5 5 4: 0 0 8 5: there are a number of programs 0 0 2 6: other agencies run our programs 0 0 NA
Explanation
num()is a function which uses the regular expression\\dto extract all strings which consist of contiguous digits (aka integer numbers), coerces them to type integer, and computes therowwisesum of the extracted numbers (as requested in OP's last sentence).txt()is a function which removes all strings which consist of contiguous digits (aka integer numbers), removes whitespace from start and end of the strings and reduces repeated whitespace inside the strings.\(x)is a new shortcut forfunction(x)introduced with R version 4.1- The next steps implement OP's proposed approach in data.table syntax, by and large:
- For each character column in
df, both functionstxt()andnum()are applied. The two resulting vectors are turned into a data.table as a partial result. Note thatcbind()cannot be used here as it would return a character matrix. The final result is a data.table where the column names have been renamed automagically. - Then, a data.table is created which consists of all remaining, non-character columns.
- Finally, both data.tables are combined into one using
cbind().
- For each character column in
CodePudding user response:
Here's a dplyr solution using regular expression:
library(stringr)
library(dplyr)
df %>%
mutate(
a.text = gsub("(^|\\s)\\d ", "", a),
a.num = str_extract_all(a, "\\d "),
b.text = gsub("(^|\\s)\\d ", "", b),
b.num = str_extract_all(b, "\\d ")
) %>%
select(c(4:7,3))
a.text a.num b.text b.num c
1 There are programs 5 four 2
2 - adult programs,- youth programs 2, 3 we don't collect this 6
3 25 from us, more from others 5 5
4 8
5 there are a number of programs 2
6 other agencies run our programs NA