I have a dataframe with information concerning the date and the cluster that it belongs (it was done before based on collected temperatures for each day). I want to plot this data in sequence, like a stacked bar chart, changing the color of each element according to the assigned cluster. Here it is my table (the info goes up to 100 days):
| Date | order | ClusterNo2 | constant |
|---|---|---|---|
| 2020-08-07 | 1 | 3.0 | 1 |
| 2020-08-08 | 2 | 0.0 | 1 |
| 2020-08-09 | 3 | 1.0 | 1 |
| 2020-08-10 | 4 | 3.0 | 1 |
| 2020-08-11 | 5 | 1.0 | 1 |
| 2020-08-12 | 6 | 1.0 | 1 |
| 2020-08-13 | 7 | 3.0 | 1 |
| 2020-08-14 | 8 | 2.0 | 1 |
| 2020-08-15 | 9 | 2.0 | 1 |
| 2020-08-16 | 10 | 2.0 | 1 |
| 2020-08-17 | 11 | 2.0 | 1 |
| 2020-08-18 | 12 | 1.0 | 1 |
| 2020-08-19 | 13 | 1.0 | 1 |
| 2020-08-20 | 14 | 0.0 | 1 |
| 2020-08-21 | 15 | 0.0 | 1 |
| 2020-08-22 | 16 | 1.0 | 1 |
Obs: I can't simply group the data by cluster because the plot should be sequential. I thought writing a code to identify the number of elements of each cluster sequentially, but then I will face the same problem for plotting. Someone know how to solve this?
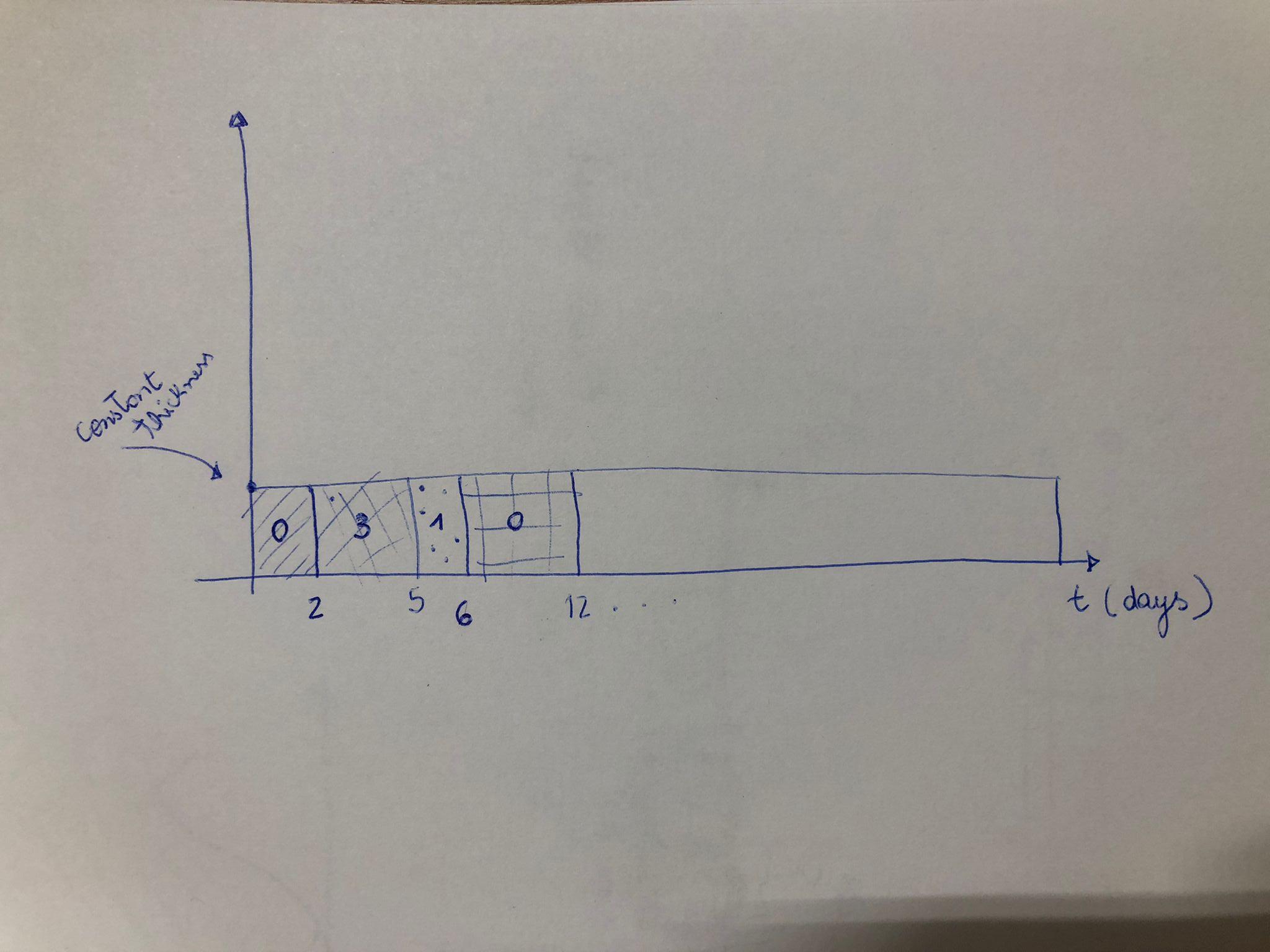
The expected result should be something like this (the numbers inside the bar representing the cluster, the x-axis the time in days and the bar width the number of observed days with the same cluster in order :
CodePudding user response:
You could use the dates for the x-axis, the 'constant' column for the y-axis, and the Cluster id for the coloring.
import matplotlib.pyplot as plt
import pandas as pd
import numpy as np
N = 100
df = pd.DataFrame({'Date': pd.date_range('2020-08-07', periods=N, freq='D'),
'order': np.arange(1, N 1),
'ClusterNo2': np.random.randint(0, 4, N).astype(float),
'constant': 1})
df['ClusterNo2'] = df['ClusterNo2'].astype(int) # convert to integers
fig, ax = plt.subplots(figsize=(15, 3))
num_clusters = df['ClusterNo2'].max() 1
colors = plt.cm.Set2.colors
ax.bar(x=range(len(df)), height=df['constant'], width=1, color=[colors[i] for i in df['ClusterNo2']], edgecolor='none')
ax.set_xticks(range(len(df)))
labels = ['' if i % 3 != 0 else day.strftime('%d\n%b %Y') if i == 0 or day.day <= 3 else day.strftime('%d')
for i, day in enumerate(df['Date'])]
ax.set_xticklabels(labels)
ax.margins(x=0, y=0)
fig.tight_layout()
plt.show()

CodePudding user response:
You could just plot a normal bar graph, with 1 bar corresponding to 1 day. If you make the width also 1, it will look as if the patches are contiguous.
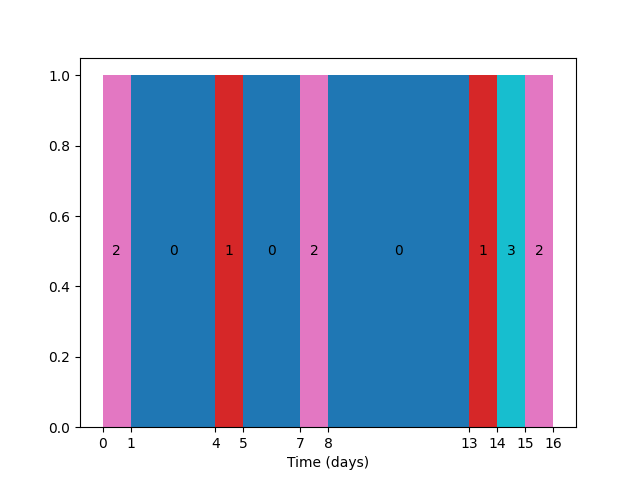
import numpy as np
import matplotlib.pyplot as plt
from matplotlib.colors import BoundaryNorm
# simulate data
total_datapoints = 16
total_clusters = 4
order = np.arange(total_datapoints)
clusters = np.random.randint(0, total_clusters, size=total_datapoints)
# map clusters to colors
cmap = plt.cm.tab10
bounds = np.arange(total_clusters 1)
norm = BoundaryNorm(bounds, cmap.N)
colors = [cmap(norm(cluster)) for cluster in clusters]
# plot
fig, ax = plt.subplots()
ax.bar(order, np.ones_like(order), width=1, color=colors, align='edge')
# xticks
change_points = np.where(np.diff(clusters) != 0)[0] 1
change_points = np.unique([0] change_points.tolist() [total_datapoints])
ax.set_xticks(change_points)
# annotate clusters
for ii, dx in enumerate(np.diff(change_points)):
xx = change_points[ii] dx/2
ax.text(xx, 0.5, str(clusters[int(xx)]), ha='center', va='center')
ax.set_xlabel('Time (days)')
plt.show()