Machine: three virtual machines, 4 core, memory 10 g (installed cdh5.3.3, installation is memory of 4 g, then enlarge to 10 g)
Question:
(1) for local deployment model, the three assignments can run normally, can receive kafka, and processing,
/usr/lib/spark - 1.3.1 - bin - hadoop2.4/bin/spark - submit - class com. - jars XXX XXX. The jar - master the local [2], the conf spark. The UI. The port=4042 - executor - memory 768 m yyy jar
(all three assignments by the above command run on three machines respectively)
(2) for standalone deployment model, a receiving data, can be used for production and success to kafka, but no processing data assignments and homework c b , assignments and homework c b have received kafka message unknown
/usr/lib/spark - 1.3.1 - bin - hadoop2.4/bin/spark - submit - class com. - jars XXX XXX. The jar - master spark://hdp5:7077 - the conf spark. The UI. The port=4042 - executor - memory 1 g - total - executor - cores 3 yyy. Jar
(all three assignments by the above command run on three machines respectively)
Check the hdp5:8080
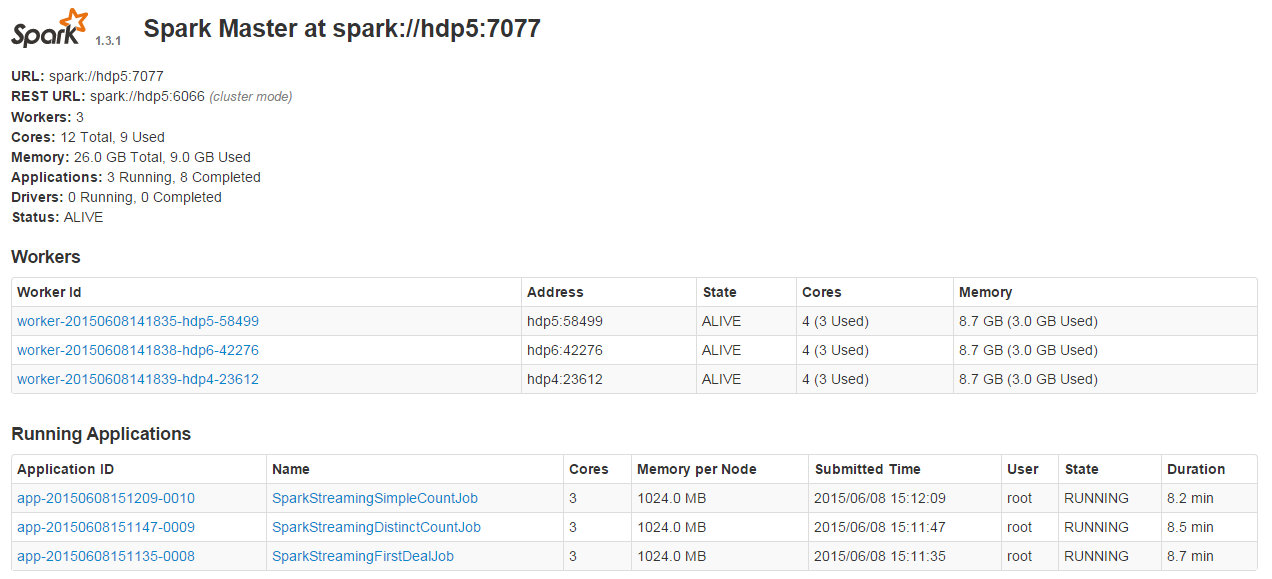
Standalone resources lead to enough or not, I feel as an input dstream will occupy a nuclear, but the feeling of auditing is enough ah,
, three (3) the deployment model for yarn - cluster operations through the spark - submit after the run, only a job is running state, the other two have been accepted?
CodePudding user response:
The spark - default. Conf
Spark. The serializer org. Apache. Spark. The serializer. KryoSerializer
Spark. Driver. The memory of 768 m
Spark. Executor. 2 g memory
Spark. Streaming. Unpersist true
Spark. Streaming. Receiver. WriteAheadLog. Enable false
Spark. Local. Dir/data1/data/spark and/data2/data/spark,/data3/data/spark
Spark. Default. Parallelism 9
The spark. Shuffle. ConsolidateFiles true
The spark. Storage. MemoryFraction 0.6
Spark. Driver. ExtraJavaOptions - XX: XX: + DisableExplicitGC - + UseConcMarkSweepGC - XX: XX: + CMSParallelRemarkEnabled - + UseCMSCompactAtFullCollection - XX: XX: + UseCMSInitiatingOccupancyOnly CMSInitiatingOccupancyFraction=70
Spark. Executor. ExtraJavaOptions - XX: XX: + DisableExplicitGC - + UseConcMarkSweepGC - XX: XX: + CMSParallelRemarkEnabled - + UseCMSCompactAtFullCollection - XX: XX: + UseCMSInitiatingOccupancyOnly CMSInitiatingOccupancyFraction=70
The spark - env. Sh
Export JAVA_HOME=/usr/Java/jdk1.7.0 _67
Export SCALA_HOME=/usr/lib/scala - 2.11.4
Export SPARK_MASTER_IP=hdp5
# export SPARK_WORKER_MEMORY=768 m
SPARK_WORKER_DIR=/data3/logs/spark
Export HADOOP_CONF_DIR=/etc/alternatives/hadoop - conf
Export SPARK_LIBRARY_PATH=$SPARK_LIBRARY_PATH:/usr/lib/hadoop/lib/native
CodePudding user response:
There's no more spark streaming operation at the same time run the scene, how to deploy this side also difficult, dizzy deadCodePudding user response:
Configuration problem, do you have a limited number change execotor start,CodePudding user response:
The first task is not specified executor - coresCodePudding user response:
- total - executor - cores 3 is too little? You are a total of 12 cores, fully open bai