Abstract data sets: provide a distributed play type data set (RDD, ResilientDistributed Dataset) abstract, RDD based conversion operation between the translated to RDD directed acyclic graph (DAG), at the same time RDD conversion operator (transformation) of delayed the scheduler to DAG line optimization, which makes the SPARK is no longer such as MR support only map - reduce two step calculation, but a multi-step DAG task, another RDD provides caching mechanism, data sets can be cached in memory for reuse, improve computing performance,
High fault tolerance: the "origin" RDD abstract memory information, namely own RDD and parents RDD dependencies, so the SPARK of the loss of data for calculating based on dependency heavy fault-tolerant mechanism, at the same time also provide checkpoint fault-tolerant,
More computing paradigm support: SPARK support for multiple computing model, since the SPARK to release, SPARK community gradually develop sparksql, SPARK streaming, SPARK mllib, SPARK graghx multiple models, such as libraries, to do a stack type support, SQL query (structured data analysis), flow computation, machine learning, figure calculation and various calculation models,
High usability: the SPARK concise API and multi-language support, to the upper users provide a good development experience,
Compatibility: the SPARK is there is a growing ecosystem, and the perfect combination with the hadoop ecosystem, lead to more users to hug the SPARK,
Based on the above advantages of the SPARK, the SPARK has been widely used in machine learning, ETL, business intelligence (BI, interactive analysis and other fields, this paper mainly introduces the SPARK (SQL),
From market analysis results and the professional consultancy report data we learn, both in the field of enterprise and telecommunication field, the current big data applications, at least half of the application is SQL analysis/statistics class, SPARK SPARK within the ecological stack SQL components, due to its nature and SPARK community highly integration, support the cache table column type, docking a variety of data sources and docking, compatible with the advantages of the hive grammar/metastore, is undoubtedly the SQL on hadoop optimization scheme,
SPARK community status quo of SQL
Spark SQL is Spark community introduced in version 1.0, about the Spark SQL and shark, hive on the relationship between the Spark can see databricks blog:
https://databricks.com/blog/2014/07/01/shark-spark-sql-hive-on-spark-and-the-future-of-sql-on-spark.html
The spark SQL architecture diagram
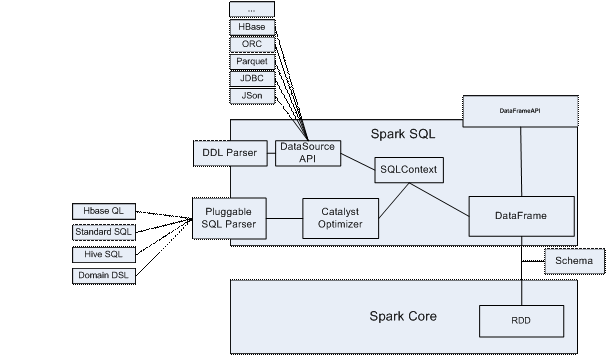
Spark SQL as the spark community is the most active component, has after 1.0 1.4 multiple versions of the iteration, and graduated from the alpha version 1.3, spark after 1.3 SQL to provide stable API support, and to ensure that future versions of the forward compatibility, the current community spark SQL version has relatively complete, complete and ongoing work mainly include:
, extensible SQL optimizer based on functional catalyst, including SQL parsing, analysis, optimization process
Grammar, support the standard grammar and compatible with most of the hive, basic meet business needs, including cube/rollup, window function, query support, support CTE, the join type support, support dynamic partitioning, spark SQL also contains some traditional SQL support but the grammar of the hive does not support, such as non - equal join, join on condition, etc., in addition, the spark provide SQL parser plug-in support SQL, the user can according to their business custom DSL/SQL syntax,
Supports multiple data sources to read and write and docking, the built-in support JDBC, parquet, such as json, ORC
Complex data type support, including array, map, struct etc.
Hive version more metadata docking, without having to recompile the spark, can achieve the Hive multiple versions of the metadata switch
Code generation, improve expression evaluation efficiency
, memory management framework based on heap memory, greatly enhance the spark stability and performance of SQL
Customized serializer, Spark SQL implementation, optimize SQL shuffle Spark cost, improve SQL performance
LLVM optimization,
DataFrame API, more friendly performance better analytical API
Overall, the spark SQL feature availability/usability related development has been completed, the main focus on further enhance spark SQL performance and stability (https://databricks.com/blog/2015/04/28/project-tungsten-bringing-spark-closer-to-bare-metal.html),
SPARK SQL application scenario for the
Spark due to its syntax/SQL optimizer scalability, with the support of the excellent analytical API, the standard API support for a variety of data sources, apply to [Y (1) the following scene:
Analysis system, [Y (2) meter application, such as in the field of operators, all kinds of dimension calculation of various kinds of KPI;
Analysis and mining, comprehensive scenario, or a client is currently query class analysis but the application of data mining on the plan in the next class analysis, the main benefit from the spark SQL itself strong analysis ability, and stack with the mllib integration ability;
The federated query, because sparksql support for multiple data sources, it is enough to support from multiple data sources to federated query query data analysis,
huawei in SPARK SQL enhancement work
Although the spark SQL powerful data source integration analysis ability, as well as the performance good user friendly API support, but the spark SQL in the following two types of applications or slightly less than:
Big data, data warehouse applications, this is mainly restricted to spark the syntax of the SQL support, although the spark SQL has been basically completed compatibility of hive grammar development, but its in the standard grammar and lack of larger, such as the subquery (including correlated sub-query) support, exist, in support, it is difficult to make the traditional database used to hadoop smooth transition;
Cloud, big data query service, restricted to sparksql security, the lack of rights, the current community in a safe, little permissions input, which makes the spark SQL cloud blocked,
In addition, catalyst optimizer to join more complex SQL under the optimization rules, such as weak, easy to cause the cartesian product generated, causing a sharp drop in performance or even could not work out the final result,
Huawei is carried out on the big data team in the community sparksql plug-in enhancements in great quantities, make the enhanced spark SQL enough to deal with enterprise users from traditional analysis database to hadoop data migration of system transition, and based on the spark SQL query analysis of cloud services, huawei's big data team in spark SQL enhancement are:
· to hive ql grammar as well as standard feature enhancements, including exist/in support, correlated sub-query support, the filter in the complex query support, do not do any modification can run successfully TPCDS test set, the enhanced version for huawei big data team spark and hive SQL syntax (https://github.com/hortonworks/hive-testbench) [Y (3), the standard SQL syntax compatibility (http://www.tpc.org/tpcds/)

Sql parallelism support, concurrency bug fixes, support for multiple session concurrently running Sql
Permissions, security enhancements, supporting role, can control the user's table, query, update permissions, at the same time provide access control for the
Catalyst, the optimizer enhanced, in the community on the basis of the optimizer is mainly do the following several aspects to enhance,
1) joinreordering and join on condition to optimize the cartesian product, can reach hundreds of times performance improvement;

2) constant folding3) operator reordering reducing node input data and transport costs;
4) expression is optimized solution efficiency, especially some machine generated SQL, use the rules of the optimizer can significantly improve performance,
5) pre - partial - aggregation, the optimization algorithm can be used to optimize the aggregation function, at the same time can also reduce the join the input size,
6) remove unnecessary exchange to remove unnecessary shuffle process;
7) [data skipping on fine blocklevel filter feature] based on the work load predict optimization;
8) Shared SQL statements, the SQL is useful for complex, avoid duplication cost analysis optimization time.
9) dynamic partitioning performance optimization, the current community dynamic partitioning code path cost very much memory, and poor performance, the main reason is that each task to each partition boot file stream to write data to the system load is too large, through data rearrangement in advance can greatly reduce the pressure of GC dynamic partitioning, improve dynamic partitioning,
Huawei, in short, the catalyst of the optimizer to enhance real application scenario based on the customer, at the same time according to different user's work load level optimization modeling, data organization will reduce the amount of data read from the sources;
Datasource, support, increased the orc, hbase, cube and other data sources support
summary
In conclusion, the spark of SQL extensibility allows the user to easily embed their grammar parser or add features, while at the same time allowing constantly add new optimization in the understanding of the business rules and data sources, is because the advantage of spark SQL on the architecture, the spark heat SQL in the community, has a large number of contributors, it is worth mentioning, huawei's big data spark team has 10 + contributors in the community, the cumulative contribution patch + 200, at the same time, the distributions of us passed the Databricks official certification, we believe that with the subsequent release, spark SQL will get great promotion in the performance and stability, at the same time, huawei's big data later gradually will spark team internal optimization features and grammar characteristics contribute back to the community,
Finally, huawei's big data spark team hope you will join us, let's play the spark!!!!!!nullnullnullnullnullnullnullnullnullnullnullnull