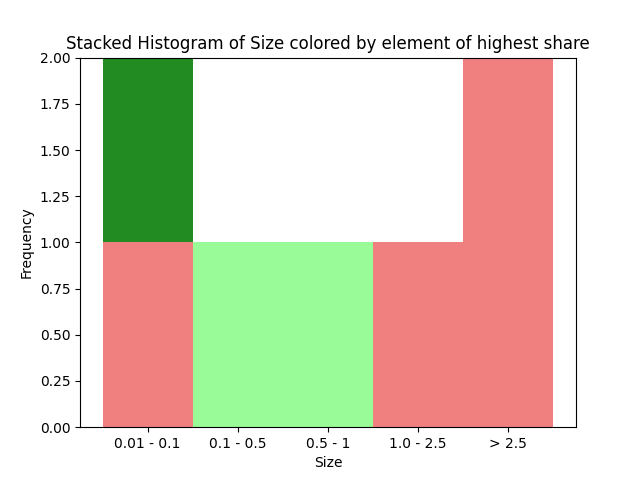
I am working on a code of a stacked histogram and I need help arranging the bins in the order if this is possible.
0.01 - 0.1, 0.1 - 0.5, 0.5 - 1.0, 1.0 - 2.5, > 2.5
Right now, my histogram looks like this:
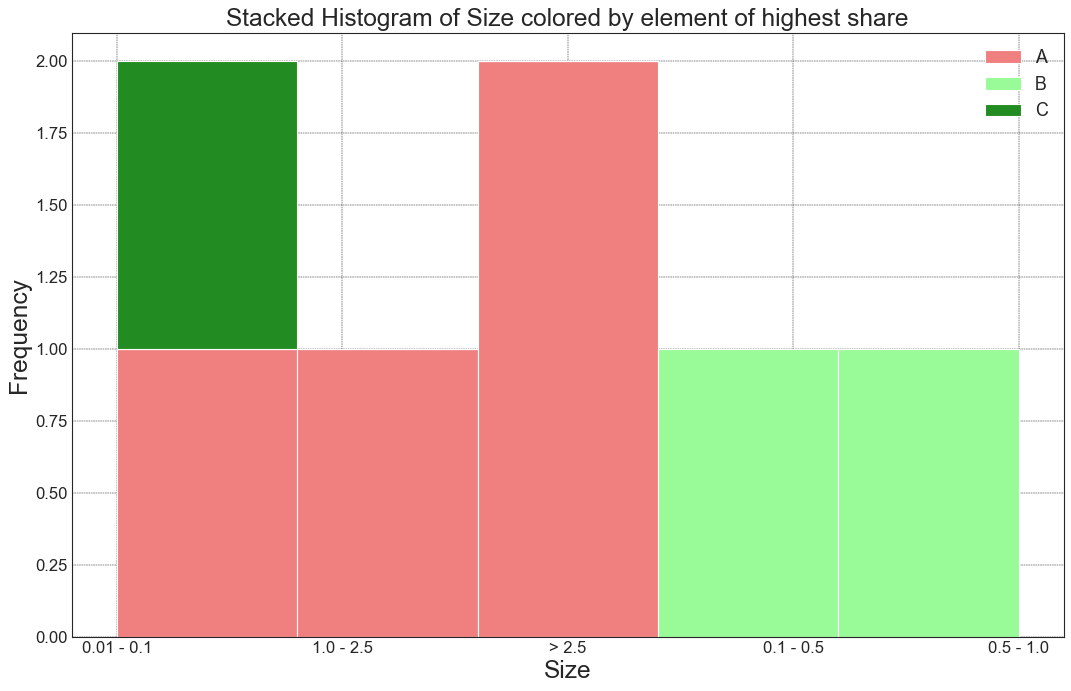
with the order of bins being:
0.01 - 0.1, 1.0 - 2.5, > 2.5, 0.1 - 0.5, 0.5 - 1.0
Code:
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
data = [['0.01 - 0.1','A'],['0.1 - 0.5','B'],['0.5 - 1.0','B'],['0.01 - 0.1','C'],['> 2.5','A'],['1.0 - 2.5','A'],['> 2.5','A']]
df = pd.DataFrame(data, columns = ['Size','Index'])
### HISTOGRAM OF SIZE
df_new = df.sort_values(['Size'])
x_var = 'Size'
groupby_var = 'Index'
df_new_agg = df_new.loc[:, [x_var, groupby_var]].groupby(groupby_var)
vals = [df_new[x_var].values.tolist() for i, df_new in df_new_agg]
list_of_colors_element = ['lightcoral','palegreen','forestgreen']
# Draw
plt.figure(figsize=(16,10), dpi= 80)
colors = [plt.cm.Spectral(i/float(len(vals)-1)) for i in range(len(vals))]
n, bins, patches = plt.hist(vals, df_new[x_var].unique().__len__(), stacked=True, density=False, color=list_of_colors_element)
# Decorations
plt.legend({group:col for group, col in zip(np.unique(df_new[groupby_var]).tolist(), list_of_colors_element)}, prop={'size': 16})
plt.title("Stacked Histogram of Size colored by element of highest share", fontsize=22)
plt.xlabel(x_var, fontsize=22)
plt.ylabel("Frequency", fontsize=22)
plt.grid(color='black', linestyle='--', linewidth=0.4)
plt.xticks(range(5),fontsize=15)
plt.yticks(fontsize=15)
plt.show()
Any help is appreciated!
CodePudding user response:
You can use:
piv = df_new.assign(dummy=1) \
.pivot_table('dummy', 'Size', 'Index', aggfunc='count', fill_value=0) \
.rename_axis(columns=None)
ax = piv.plot.bar(stacked=True, color=list_of_colors_element, rot=0, width=1)
plt.show()
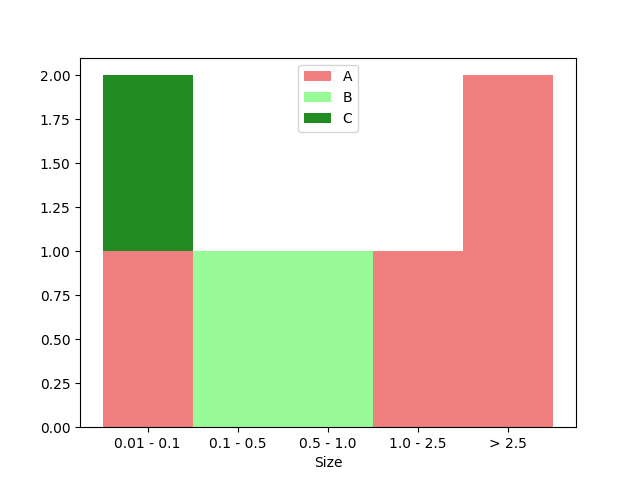
CodePudding user response:
I think I'd take a different route and represent the input data differently altogether to make the code easier to read.
import matplotlib.pyplot as plt
labels = ['0.01 - 0.1', '0.1 - 0.5', '0.5 - 1', '1.0 - 2.5', '> 2.5']
A = [1, 0, 0, 1, 2]
B = [0, 1, 1, 0, 0]
C = [1, 0, 0, 0, 0]
width = 1
fig, ax = plt.subplots()
ax.bar(labels, A, width, label='A', color='lightcoral')
ax.bar(labels, B, width, bottom=A, label='B', color='palegreen')
ax.bar(labels, C, width, bottom=A, label='C', color='forestgreen')
ax.set_ylabel('Frequency')
ax.set_xlabel('Size')
ax.set_title("Stacked Histogram of Size colored by element of highest share")
plt.show()