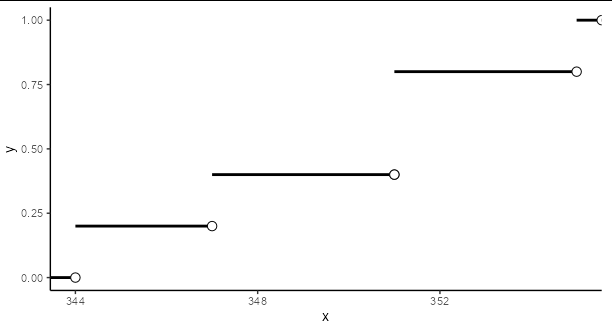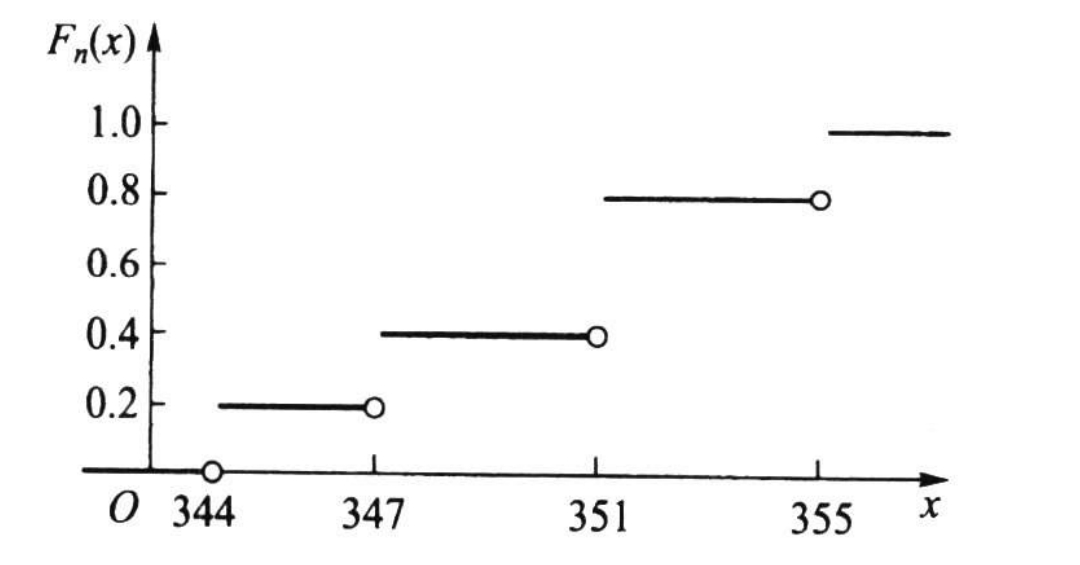
This is the data x1:344,347,351,351,355 I need to plot the empirical cumulative distribution function based on the data above,and here is my solution
point<-na.omit(data$x1)
point<-point[!duplicated(point)]
point<-point[order(point)]
prob<-ecdf(data$x1)
prob<-prob(data$x1)
prob<-prob[order(prob)]
prob<-na.omit(prob)
x1<-data$x1[order(data$x1)]
x1<-c(340,344,347,351,355)
x2<-c(344,347,351,355,360)
prob2<-prob[!duplicated(prob)]
data1<-cbind(x1,x2,prob,point,prob2)
data1<-as.data.frame(data1)
ggplot(data=data1)
geom_segment(mapping = aes(x = x1,xend = x2,y = prob,yend = prob))
scale_x_continuous(limits = c(340,360))
scale_y_continuous(limits = c(0,1))
geom_point(mapping = aes(x = point ,y = prob2))
I think this is too complicated and it is not like the plot on the image, but i really dont know how to simplify it without using base plot()(or the stepfun() because it looks not so well). I've been thinking for several hours ,really appreciate your help!
CodePudding user response:
You could do it manually by creating a little data frame of the values you want to plot.
library(ggplot2)
data <- c(344, 347, 351, 351, 355)
df <- data.frame(x = c(-Inf, data),
xend = c(data, Inf),
y = c(0, 0.2, 0.4, 0.4, 0.8, 1))
ggplot(df, aes(x, y))
geom_segment(aes(xend = xend, yend = y), size = 1)
geom_point(aes(x = xend), shape = 21, fill = "white", size = 3)
theme_classic()