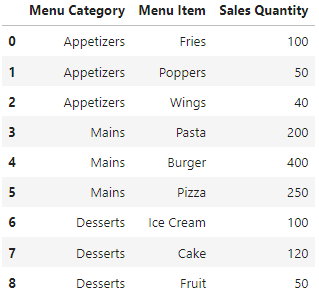
I have the following Pandas DataFrame:
# Create DataFrame
import pandas as pd
data = {'Menu Category': ['Appetizers', 'Appetizers', 'Appetizers', 'Mains', 'Mains',
'Mains', 'Desserts', 'Desserts', 'Desserts'],
'Menu Item': ['Fries', 'Poppers', 'Wings', 'Pasta', 'Burger', 'Pizza',
'Ice Cream', 'Cake', 'Fruit'],
'Sales Quantity': [100, 50, 40, 200, 400, 250, 100, 120, 50],
}
df = pd.DataFrame(data)
df
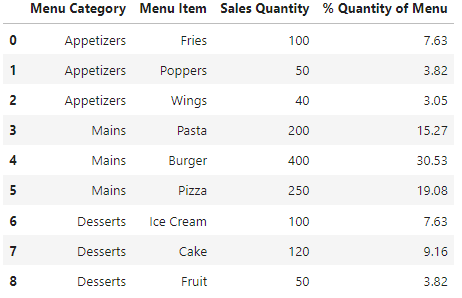
I would like to add two columns. 1) that shows the % Quantity of the Menu that each item represents (entire menu being this dataset), and 2) that shows the % Quantity of the Menu Category the item belongs to (like what percentage of the Sale Quantity does Fries represent of the Appetizers group, i.e. (100/190) * 100).
I know how to get the first column mentioned:
# Add % Quantity of Menu Column
percent_menu_qty = []
for i in df['Sales Quantity']:
i = round(i/df['Sales Quantity'].sum() * 100, 2)
percent_menu_qty.append(i)
df['% Quantity of Menu'] = percent_menu_qty
df
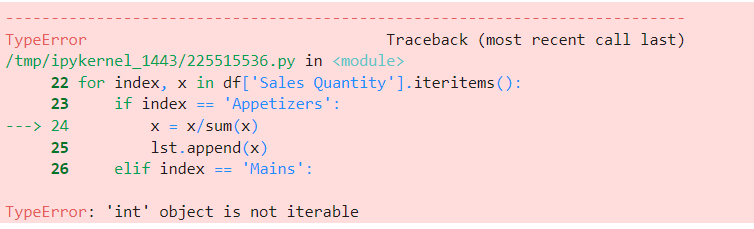
What I am not sure how to do is the second one. I have tried by setting Menu Category as the index and doing the following:
# Add % Quantity of Menu Category Column
df = df.set_index('Menu Category')
lst = []
for index, x in df['Sales Quantity'].iteritems():
if index == 'Appetizers':
x = x/sum(x)
lst.append(x)
elif index == 'Mains':
x = x/sum(x)
lst.append(x)
elif index == 'Desserts':
x =x/sum(x)
lst.append(x)
lst
I know I need to somehow set a condition for each Menu Category that if index == 'a certain menu category value' then divide quantity by the sum of that menu category. Thus far I haven't been able to figure it out.
CodePudding user response:
First of all, I would like to compliment you on using comprehensive row by row. I still use them for time to time, because I consider loops to be easier for someone else to read and understand what the principle is without running the code itself.
But ye. For this solution, I have created a couple one liners and let me explain what each are.
df['% Quantity of Menu'] = ((df['Sales Quantity']/df['Sales Quantity'].sum())*100).round(2)
For your first problem, instead of looping row to row, this divides the column value with a scalar value (which is the total of the column df['Sales Quantity'].sum()), then the ratio is multiplied with 100 for percentage, then round off at 2 decimal points.
df['%Qty of Menu Category'] = ((df['Sales Quantity']/df.groupby(['Menu Category'])['Sales Quantity'].transform('sum'))*100).round(2)
So, for the second problem, we need to divide the column value with the total of each corresponding category instead of the whole column. So, we get the value with groupby for each category df.groupby(['Menu Category'])['Sales Quantity'].transform('sum'), then did the same as the first one, by replacing the portion of the code.
Here, why do we use df.groupby(['Menu Category'])['Sales Quantity'].transform('sum') instead of df.groupby(['Menu Category'])['Sales Quantity'].sum()? Because for division of a series can be done either with a scalar or with a series of same dimension, and the former way gives us the series of same dimension.
df['Sales Quantity']
0 100
1 50
2 40
3 200
4 400
5 250
6 100
7 120
8 50
Name: Sales Quantity, dtype: int64
df.groupby(['Menu Category'])['Sales Quantity'].transform('sum')
0 190
1 190
2 190
3 850
4 850
5 850
6 270
7 270
8 270
Name: Sales Quantity, dtype: int64
df.groupby(['Menu Category'])['Sales Quantity'].sum()
Menu Category
Appetizers 190
Desserts 270
Mains 850
Name: Sales Quantity, dtype: int64
CodePudding user response:
I think you're looking for groupby transform sum to get the "Category" sums; then divide each "Sales Quantity" by their "Category" sum. This gives us the share of each menu item in their menu category.
You can also use the vectorized div method instead of loop for the first column:
df['%Qty of Menu'] = df['Sales Quantity'].div(df['Sales Quantity'].sum()).mul(100).round(2)
df['%Qty of Menu Cat'] = df.groupby('Menu Category')['Sales Quantity'].transform('sum').rdiv(df['Sales Quantity']).mul(100).round(2)
Output:
Menu Category Menu Item Sales Quantity %Qty of Menu %Qty of Menu Cat
0 Appetizers Fries 100 7.63 52.63
1 Appetizers Poppers 50 3.82 26.32
2 Appetizers Wings 40 3.05 21.05
3 Mains Pasta 200 15.27 23.53
4 Mains Burger 400 30.53 47.06
5 Mains Pizza 250 19.08 29.41
6 Desserts Ice Cream 100 7.63 37.04
7 Desserts Cake 120 9.16 44.44
8 Desserts Fruit 50 3.82 18.52