Post code directly, I basically is a case according to the website to!!!!!! As follows: not enough, only have a few left... Hope everybody to help me
Maven:
And then directly is the test code:
/* *
* access connection
*/
Public static JavaSparkContext getConnection () {
//get connection
SparkConf conf=new SparkConf (true). SetAppName (" spark and Cassandra ")
//. The set (" spark. Testing. The memory ", "2147480000")//allocated memory, the memory of less than 512 m
Set (" spark. Cassandra. Connection. The host ", "192.168.1.13");
JavaSparkContext sc=new JavaSparkContext (" spark://192.168.1.13:7077 ", "SparkOptionCassandra1", the conf);
System. The out. Println (sc) master () + ":" + sc. AppName ());
Return sc;
}
/* *
* read the spark Cassandra table data 22222
*/
Public static void getDataFromCassandra () {
JavaSparkContext sc=getConnection ();
Try {
JavaRDD
. The map (new Function
Public String call (CassandraRow CassandraRow) throws the Exception {
Return cassandraRow. ToString ();
}
});
System. The out. Println (" Data as CassandraRows: \ n "+ StringUtils. Join (" \ n", cassandraRowsRDD. Collect ()));
} the catch (Exception e) {
e.printStackTrace();
} the finally {
Sc. Stop ();
Sc. The close ();
}
}
Then an error message:
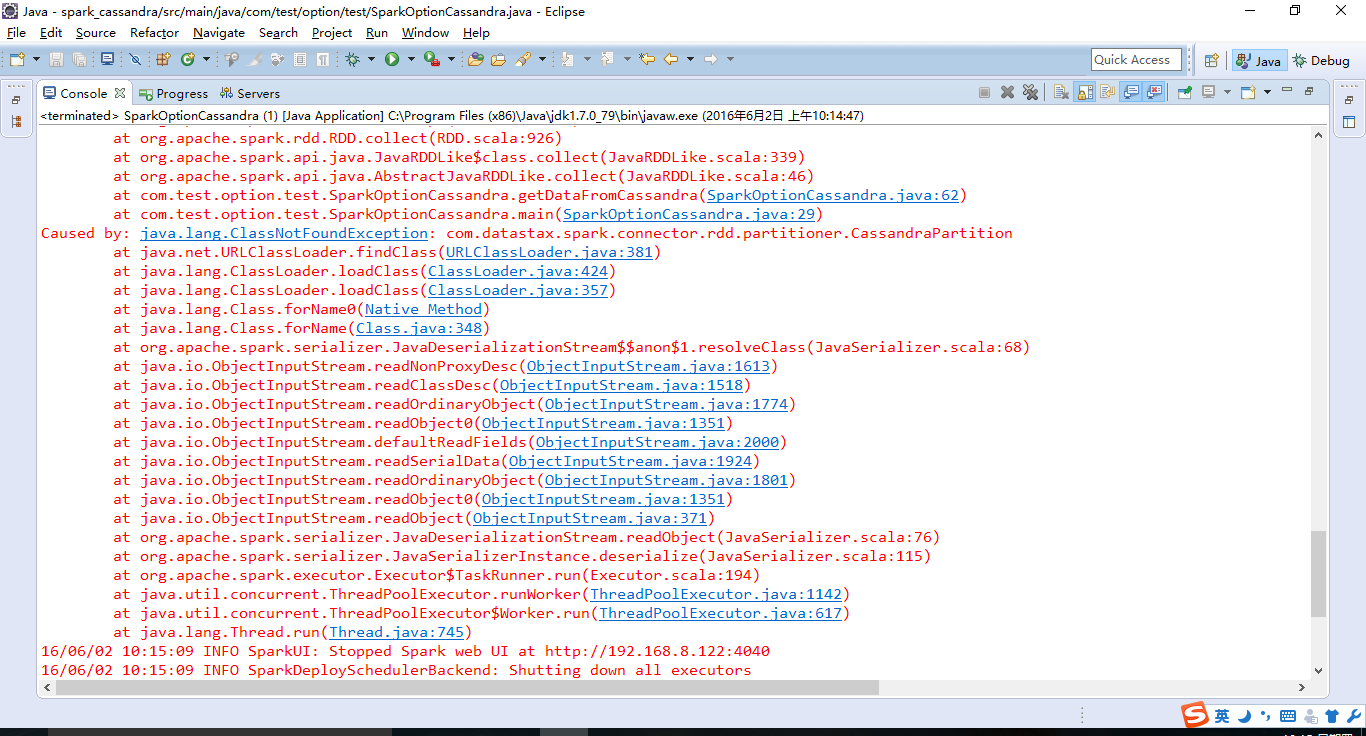
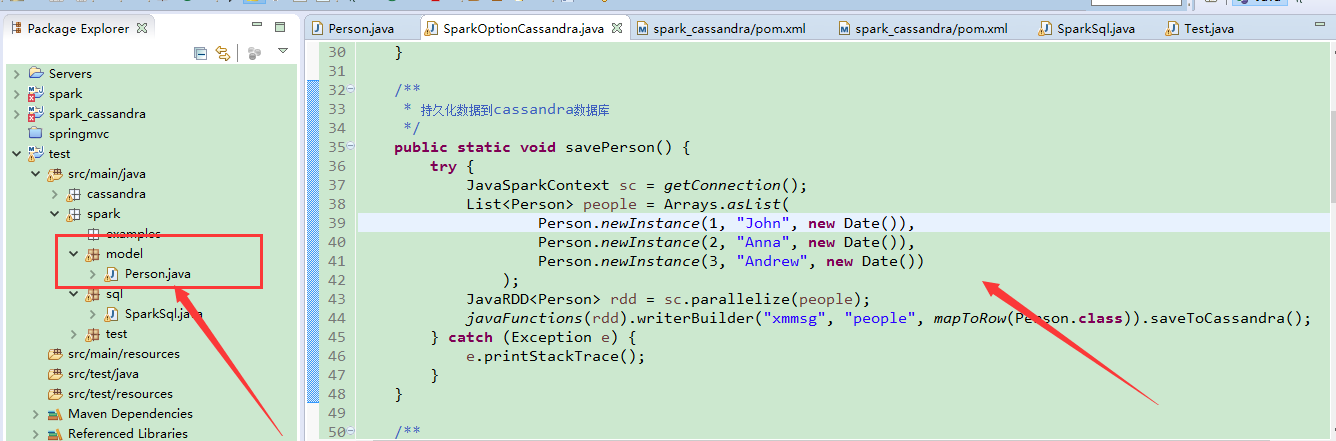
Then save is: hey
/* *
* persisting data to Cassandra database
*/
Public static void savePerson () {
Try {
JavaSparkContext sc=getConnection ();
List
Person. NewInstance (1, "John", new Date ()),
Person. NewInstance (2, "Anna", new Date ()),
Person. NewInstance (3, "Andrew", new Date ())
);
JavaRDD
JavaFunctions (RDD). WriterBuilder (" XMMSG ", "people", mapToRow (Person. Class)). SaveToCassandra ();
} the catch (Exception e) {
e.printStackTrace();
}
}
Error message:

please god help me, thank you!!!!!!!!!!!!!!!!!!!
Have a question about sparksql:
Public static void writeResouces () {
JavaSparkContext sc=getConnection (" first ", "local");
SQLContext SQLContext=new SQLContext (sc);
DataFrame df=sqlContext read (). The format (" json "). The load (" c://test//people. The json ");
//don't know why the output file is folder? The Windows and Linux the difference?
Df. Select (" name ", "age"). The write (). The format (" parquet "). The save (" c://test/namesAndAges2 parquet ");
//so to query
DataFrame df2=sqlContext. SQL (" SELECT * FROM parquet. ` c://test/namesAndAges2 parquet ");
System. The out. Println (df2. The count ());
}
Why am I in win local produce is namesAndAges2. Parquet folder, inside what things all have no,
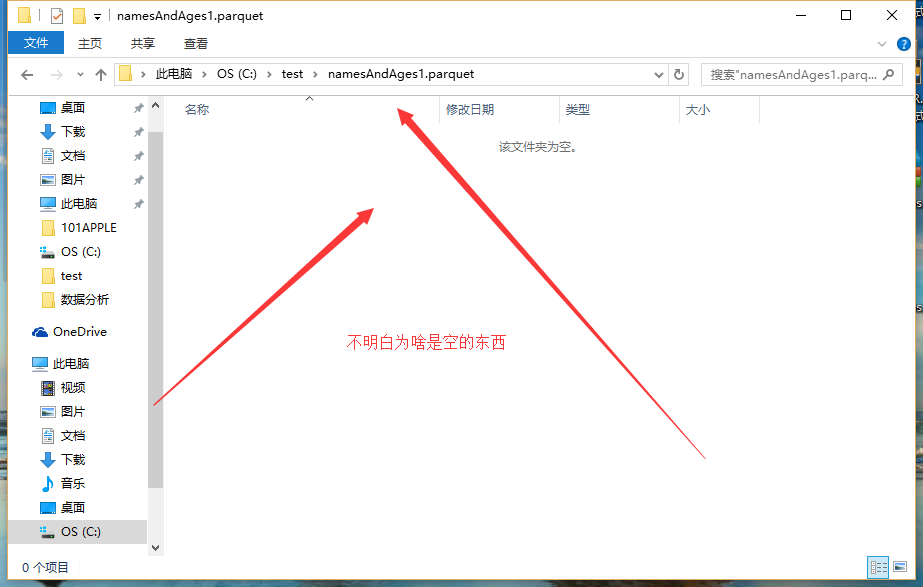
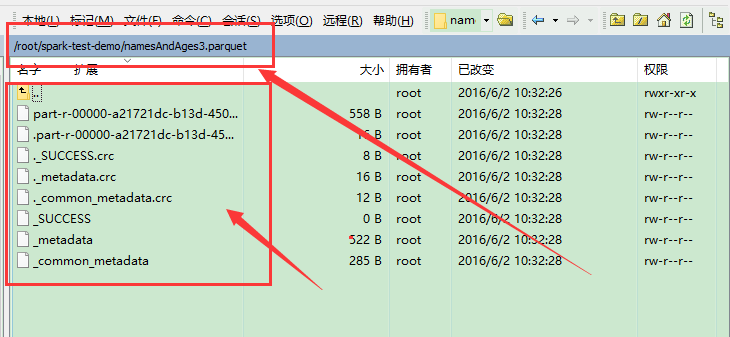
on Linux can generate the file, but can't read!!!!!
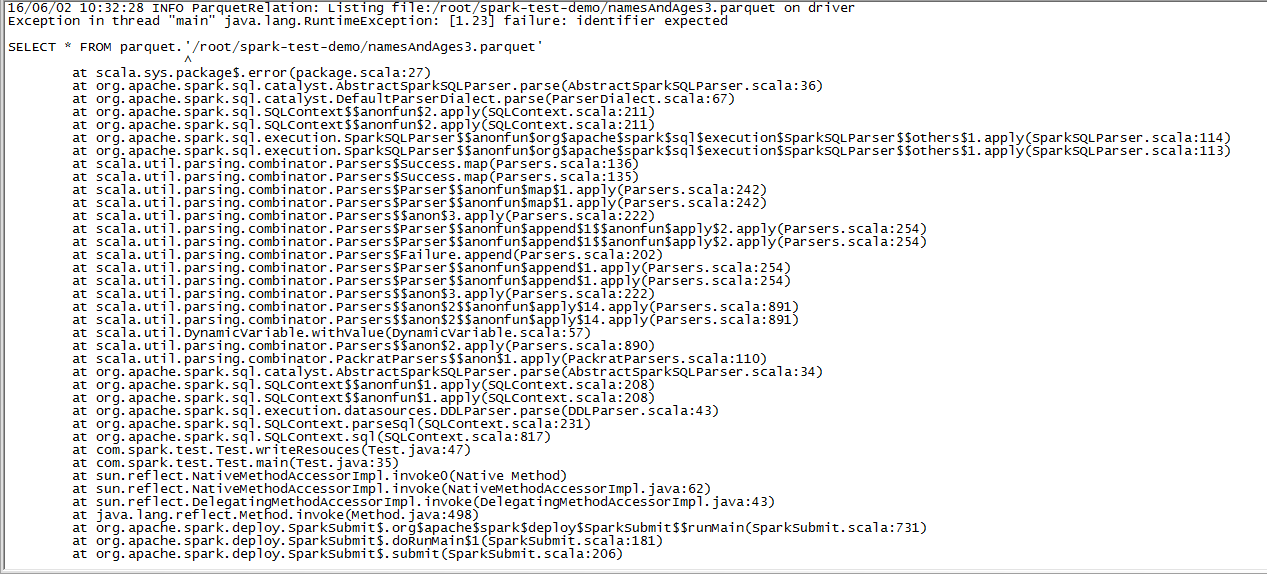
CodePudding user response:
Why no one, ah...