I have dirty grouped lists of Ids ids_group_dirty and I need to regroup it to get following results:
{dirty_grp_0: 1, 2, 3, 4, 5} (ids 1,2,3 comes together and id 4 grouped with 3 and 5 grouped with 4).
{dirty_grp_3: 6} (id 6 comes along).
I've already broken my brain :) Anyone can solve this puzzle ?
import pandas as pd
import numpy as np
ids_group_dirty = {
'dirty_grp_0': [1, 2, 3],
'dirty_grp_1': [3, 4],
'dirty_grp_2': [4, 5],
'dirty_grp_3': [6]
}
unique_ids = np.unique(np.concatenate(list(ids_group_dirty.values())))
df = pd.DataFrame(index=ids_group_dirty.keys(), columns=unique_ids)
for grp in ids_group_dirty.keys():
df.loc[grp] = np.where(df.columns.isin(ids_group_dirty[grp]), 1.0, np.nan)
df
1 2 3 4 5 6
dirty_grp_0 1.0 1.0 1.0 NaN NaN NaN
dirty_grp_1 NaN NaN 1.0 1.0 NaN NaN
dirty_grp_2 NaN NaN NaN 1.0 1.0 NaN
dirty_grp_3 NaN NaN NaN NaN NaN 1.0
Any help much appreciated !
CodePudding user response:
This looks like a graph problem, which you can solve with 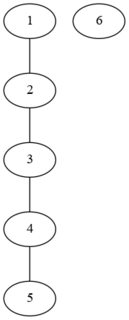
CodePudding user response:
I think dict comprehension would be the fastest. Here we are essentially creating record for each key in ids_group_dirty
pd.DataFrame({k: {i: 1 for i in v} for k, v in ids_group_dirty.items()}).T
1 2 3 4 5 6
dirty_grp_0 1.0 1.0 1.0 NaN NaN NaN
dirty_grp_1 NaN NaN 1.0 1.0 NaN NaN
dirty_grp_2 NaN NaN NaN 1.0 1.0 NaN
dirty_grp_3 NaN NaN NaN NaN NaN 1.0