Let's say I have below array of dates (not necessarily sorted):
import numpy as np
np.array(["2000Q1", "2000Q2", "2000Q3", "2000Q4", "2001Q1", "2001Q2", "2001Q3", "2001Q4", "2002Q1",
"2002Q2", "2002Q3", "2002Q4", "2003Q1", "2003Q2", "2003Q3", "2003Q4", "2004Q1", "2004Q2", "2004Q3",
"2004Q4", "2005Q1", "2005Q2", "2005Q3", "2005Q4", "2006Q1", "2006Q2", "2006Q3", "2006Q4", "2007Q1",
"2007Q2", "2007Q3", "2007Q4", "2008Q1", "2008Q2", "2008Q3", "2008Q4", "2009Q1", "2009Q2", "2009Q3",
"2009Q4"])
From this I want to create a DataFrame with 2 columns for start-date and end-date, where this dates corresponds to the starting date of a date range and ending date for that date rage spanning 4 years. This will continue for each element of above array until the last element. For example, first 3 rows of this new DataFrame would look like below
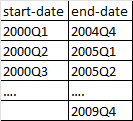
Is there any direct function/method to achieve above in Python?
CodePudding user response:
Here's one way using PeriodIndex and DateOffset functions in pandas. Note that I named your array arr below:
df = pd.DataFrame({'start-date': arr,
'end-date': (pd.PeriodIndex(arr, freq='Q').to_timestamp()
pd.DateOffset(years=4, months=10)).to_period('Q')})
Output:
start-date end-date
0 2000Q1 2004Q4
1 2000Q2 2005Q1
2 2000Q3 2005Q2
3 2000Q4 2005Q3
4 2001Q1 2005Q4
5 2001Q2 2006Q1
6 2001Q3 2006Q2
7 2001Q4 2006Q3
8 2002Q1 2006Q4
9 2002Q2 2007Q1
10 2002Q3 2007Q2
11 2002Q4 2007Q3
12 2003Q1 2007Q4
13 2003Q2 2008Q1
14 2003Q3 2008Q2
15 2003Q4 2008Q3
16 2004Q1 2008Q4
17 2004Q2 2009Q1
18 2004Q3 2009Q2
19 2004Q4 2009Q3
20 2005Q1 2009Q4
21 2005Q2 2010Q1
22 2005Q3 2010Q2
23 2005Q4 2010Q3
24 2006Q1 2010Q4
25 2006Q2 2011Q1
26 2006Q3 2011Q2
27 2006Q4 2011Q3
28 2007Q1 2011Q4
29 2007Q2 2012Q1
30 2007Q3 2012Q2
31 2007Q4 2012Q3
32 2008Q1 2012Q4
33 2008Q2 2013Q1
34 2008Q3 2013Q2
35 2008Q4 2013Q3
36 2009Q1 2013Q4
37 2009Q2 2014Q1
38 2009Q3 2014Q2
39 2009Q4 2014Q3