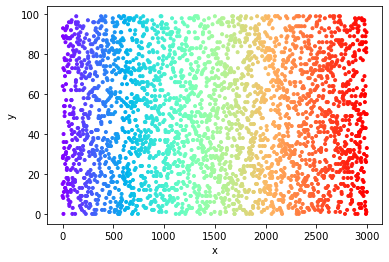
Here is an example of a scatter plot with high 2D point density, just for illustration.
How can I reduce the size of the markers to better distinguish the individual points? The size of the plot should remain as it is.
import numpy as np
import matplotlib.pyplot as plt
from sklearn import preprocessing
from matplotlib import cm
np.random.seed(10)
n=3000
x = np.arange(n)
z = np.sin(x/n)
y = np.random.randint(0, 100, size=(n))
colvals = preprocessing.minmax_scale(z)
plt.scatter(x, y, color=cm.rainbow(colvals), marker='.')
plt.xlabel('x')
plt.ylabel('y')
plt.show()
CodePudding user response:
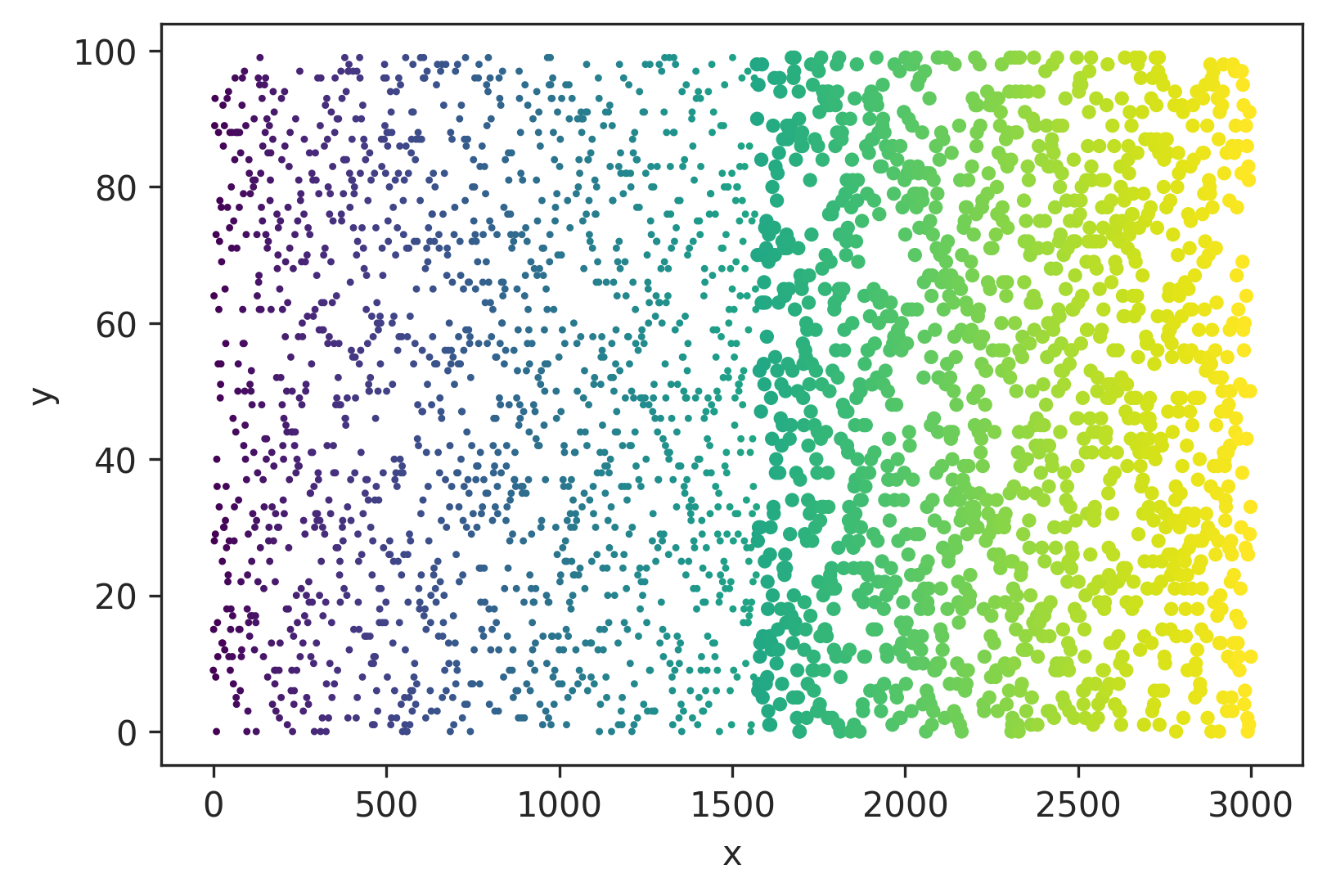
Or s can be an array of sizes that maps to every point, e.g. size 5 when z > 0.5 and size 30 otherwise:
s = np.where(z > 0.5, 5, 30)
plt.scatter(x, y, color=cm.viridis(colvals), marker='.', s=s)
Note that to match the size of scatter and plot markers, the plot marker's markersize should be the square root of the scatter marker's s:
s = 900
plt.scatter(-1, 0, s=s, color='tab:orange')
plt.plot(1, 0, 'o', markersize=s ** 0.5)