Say we have following table
df = pd.DataFrame.from_dict({
'col1': list('abcadeabba'),
'col2': range(10),
'col3': [list('abc'), list('d'), list('e'), list('ba'), list('de'),
list('abc'), list('ae'), list('e'), list('dc'), list('a')]
})
df
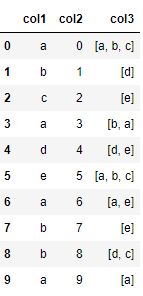
I need to col1 values as the columns, and the values under the new columns would be based on col3 with default value 0; Columns corresponding to col3 values should be 1 and others new columns values should be 0 in the row. Also, col2 should be as it is.
So, the first row would look like below

I tried pivot_table but did not find the efficient way to populate values using col3
CodePudding user response:
Use MultiLabelBinarizer for good performance solution and then append to original with DataFrame.reindex by unique values of col1, if not exist column is added 0 column(s):
from sklearn.preprocessing import MultiLabelBinarizer
mlb = MultiLabelBinarizer()
df1 = pd.DataFrame(mlb.fit_transform(df['col3']),columns=mlb.classes_)
print (df1)
a b c d e
0 1 1 1 0 0
1 0 0 0 1 0
2 0 0 0 0 1
3 1 1 0 0 0
4 0 0 0 1 1
5 1 1 1 0 0
6 1 0 0 0 1
7 0 0 0 0 1
8 0 0 1 1 0
9 1 0 0 0 0
df = df.join(df1.reindex(df['col1'].unique(), fill_value=0, axis=1))
print (df)
col1 col2 col3 a b c d e
0 a 0 [a, b, c] 1 1 1 0 0
1 b 1 [d] 0 0 0 1 0
2 c 2 [e] 0 0 0 0 1
3 a 3 [b, a] 1 1 0 0 0
4 d 4 [d, e] 0 0 0 1 1
5 e 5 [a, b, c] 1 1 1 0 0
6 a 6 [a, e] 1 0 0 0 1
7 b 7 [e] 0 0 0 0 1
8 b 8 [d, c] 0 0 1 1 0
9 a 9 [a] 1 0 0 0 0
CodePudding user response:
Here is another solution,
import pandas as pd
df = pd.DataFrame.from_dict({
'col1': list('abcadeabba'),
'col2': range(10),
'col3': [list('abc'), list('d'), list('e'), list('ba'), list('de'),
list('abc'), list('ae'), list('e'), list('dc'), list('a')]
})
dummies_ = pd.get_dummies(df['col3'].explode())
print(pd.concat([df, dummies_.groupby(dummies_.index).sum()], axis=1))
col1 col2 col3 a b c d e
0 a 0 [a, b, c] 1 1 1 0 0
1 b 1 [d] 0 0 0 1 0
2 c 2 [e] 0 0 0 0 1
3 a 3 [b, a] 1 1 0 0 0
4 d 4 [d, e] 0 0 0 1 1
5 e 5 [a, b, c] 1 1 1 0 0
6 a 6 [a, e] 1 0 0 0 1
7 b 7 [e] 0 0 0 0 1
8 b 8 [d, c] 0 0 1 1 0
9 a 9 [a] 1 0 0 0 0