I have a txt file with the following sample data:
id,001
v1,some_value
id,002
v2,some_value
v2,some_value
id,003
v2,some_value
id,004
v4,some_value
In fact, the original data is in xml/json format. But the data has been flatten. So the order of the values is important.
The idea is to get the structured data as below:

I have to R code that works as follows:
txt <- "
id,001
v1,some_value
id,002
v2,some_value
id,003
v2,some_value
id,004
v4,some_value"
existing_list <- c(id = "", v1 = "", v2 = "", v3 = "", v4 = "")
df=read.csv(textConnection(txt),header = F,stringsAsFactors = F)
id_list <- split(df, cumsum(df$V1 == "id"))
do.call(rbind, lapply(id_list, function(x) {
vec <- setNames(x$V2, x$V1)
existing_list[match(names(vec), names(existing_list))] <- vec
as.data.frame(as.list(existing_list))
}))
The problem is that it does not work for the following data
txt <- "
id,001
v1,some_value
id,002
v2,some_value
v2,some_value
id,003
v2,some_value
id,004
v4,some_value"
So my question is how to modify the R code to make it work for the second dataset.
Another aproach would be to convert the flatten txt data to json, then with a package like rjson is would be easy to parse the data. But I have no idea how to do it.
{
"items": [
{
"id": "001",
"attributes": [
{
"v1": "some_value"
}
]
},
{
"id": "002",
"attributes": [
{
"v2": "some_value"
},
{
"v2": "some_value"
}
]
},
{
"id": "003",
"attributes": [
{
"v2": "some_value"
}
]
}
]
}
[update] akrun provided a very useful answer, but then I realized that the structure can be nested.
txt <- "id,001
v1,some_value
id,002
v1,some_value
subid,002001
v2,valuev2_1
subid,002002"
This is to be transform into
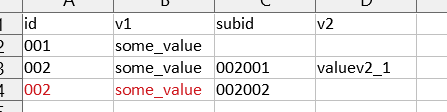
the red part to be completed.
And with the answer akrun provided, I think that we would not be able to distinguish the previous data from this one:
txt <- "id,001
v1,some_value
id,002
v1,some_value
subid,002001
subid,002002
v2,valuev2_1"
Because when examing the columns of the tibble, we have the same:
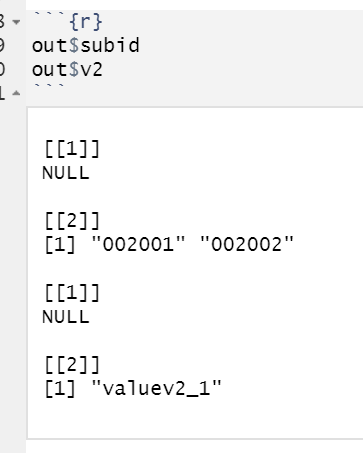
So the ideal solution would be to convert the csv to json. With the hierachical structure of the keys provided of course. But maybe I am wrong.
One step to be accomplished is to transform the tibble with list-cols into a tibble with normal columns.
CodePudding user response:
We may reshape to 'wide' format with pivot_wider
library(dplyr)
library(tidyr)
out <- df %>%
group_by(grp = cumsum(V1 == 'id')) %>%
mutate(id = first(V2)) %>%
ungroup %>%
filter(V1 != 'id') %>%
pivot_wider(names_from = V1, values_from = V2)
For the second example
library(purrr)
split(df, cumsum(df$V1 == "id")) %>%
map_dfr(~ {
x1 <- split(.x$V2, .x$V1)
mx <- max(lengths(x1))
map_dfr(x1, `length<-`, mx)}) %>%
fill(id, v1, .direction = "downup")
-output
# A tibble: 3 × 4
id v1 subid v2
<chr> <chr> <chr> <chr>
1 001 some_value <NA> <NA>
2 002 some_value 002001 valuev2_1
3 002 some_value 002002 <NA>
CodePudding user response:
Going the JSON build approach, consider migrating text data to data frame and walk down the rows:
Input
library(jsonlite)
txt <- "
id,001
v1,some_value
id,002
v2,some_value
v2,some_value
id,003
v2,some_value
id,004
v4,some_value"
Process
# BUILD DATA FRAME FROM TEXT
lines_df <- read.csv(text=txt, header=FALSE)
# BUILD NESTED LIST
lines_lst <- list(items = list())
for(row in 1:nrow(lines_df)) {
if(lines_df$V1[row] == "id"){
lines_lst$items[[row]] <- list(id = lines_df$V2[row])
lines_lst$items[[row]]$attributes <- list()
curr <- row
i <- 1
} else {
lines_lst$items[[curr]]$attributes[[i]] <- setNames(
list(lines_df$V2[row]), lines_df$V1[row]
)
i <- i 1
}
}
# REMOVE NULLs
lines_lst$items <- Filter(length, lines_lst$items)
# OUTPUT TO JSON
json_output <- toJSON(lines_lst, pretty=TRUE)
Output
json_output
{
"items": [
{
"id": ["001"],
"attributes": [
{
"v1": ["some_value"]
}
]
},
{
"id": ["002"],
"attributes": [
{
"v2": ["some_value"]
},
{
"v2": ["some_value"]
}
]
},
{
"id": ["003"],
"attributes": [
{
"v2": ["some_value"]
}
]
},
{
"id": ["004"],
"attributes": [
{
"v4": ["some_value"]
}
]
}
]
}