medicament has a list of id_questions_similar and each of those questions has some specialty_id in the other table(active_questions).I need to gather up all specialty_id matching the id_questions and create a new list containing all the specialty id's for the corresponding question id's and place in the new column in the table medicament_similar
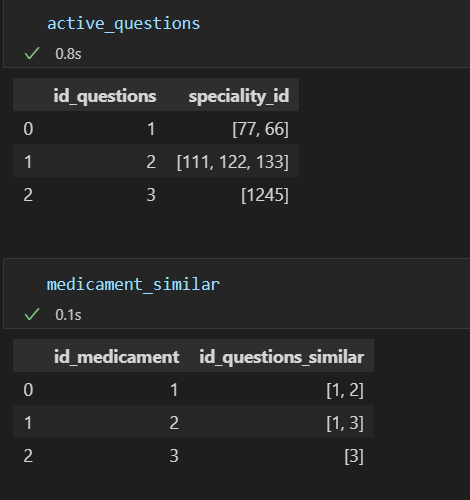
data1 = {'id_questions': [1,2,3],
'speciality_id': [[77, 66],[111, 122,133],[1245]]
}
active_questions = pd.DataFrame(data1)
active_questions
data2 = {'id_medicament': [1, 2,3],
'id_questions_similar': [[1, 2],[1,3], [3]]
}
medicament_similar = pd.DataFrame(data2)
medicament_similar
I created this sample to better explain the problem (I have two tables with more than 10000 lines) Im looking to get this result (that I did manually) :
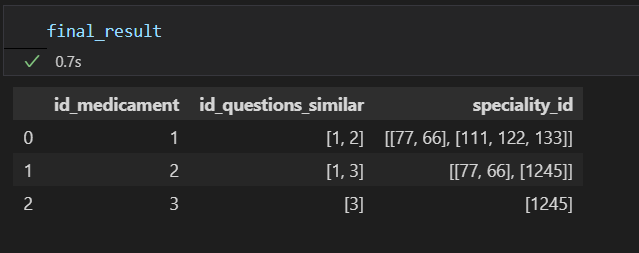
I tried this but no result:
def get_specialities(data1, data2):
for i in data1['speciality_id']:
for l in data1['id_questions']:
for k in range(len(data2['id_questions_similar'])):
drug_speciality = []
if k == l :
drug_speciality.append(data1['speciality_id'])
return drug_speciality
print(get_specialities(data_1, data_2))
CodePudding user response:
I did it like this. Probably can do everything on pandas and more optimally..? data 1['id_questions'] is looking for an occurrence in data 2['id_questions_similar'][i]. Based on these occurrences, indexes are calculated and values from 'questions['speciality_id']' are obtained.
import pandas as pd
data1 = {'id_questions': [1, 2, 3],
'speciality_id': [[77, 66], [111, 122, 133], [1245]]
}
active_questions = pd.DataFrame(data1)
data2 = {'id_medicament': [1, 2, 3],
'id_questions_similar': [[1, 2], [1, 3], [3]]
}
questions = pd.DataFrame(data2)
even_numbers = list(range(len(data2['id_questions_similar'])))
for i in range (0, len(data2['id_questions_similar'])):
qqq = list(filter(lambda aaa: aaa in data1['id_questions'], data2['id_questions_similar'][i]))
print(qqq)
index_ = []
count_ = len(qqq)
for k in range(0, count_):
ind = data1['id_questions'].index(qqq[k])#index
if count_ == 1:
even_numbers[i] = data1['speciality_id'][ind]
continue
index_.append(data1['speciality_id'][ind])#values
if count_ > 1:
even_numbers[i] = index_
questions['speciality_id'] = even_numbers
print(questions)