Plotting scatter distribution for binary classification ['cat', 'dog']:
X, y = make_classification(n_samples=1000, n_features=2, n_redundant=0,
n_clusters_per_class=1, weights=[0.9], flip_y=0, random_state=1,)
counter = Counter(y)
for label, _ in counter.items():
row_ix = np.where(y == label)[0]
plt.scatter(X[row_ix, 0], X[row_ix, 1], label=label)
plt.legend()
plt.show()
output:
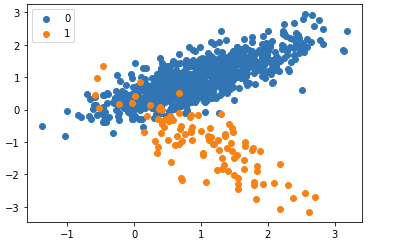
I wanted to replace 0, 1 legend with cat, dog. Here I go:
for label, _ in counter.items():
row_ix = np.where(y == label)[0]
plt.scatter(X[row_ix, 0], X[row_ix, 1], label=['cat', 'dog'])
plt.legend()
plt.show()
output:
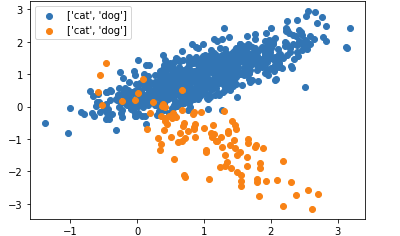
CodePudding user response:
You need to change the value of the legend's label in every iteration of the for loop, one possibility being the use of zip
for item, animal in zip(counter.items(), ['cat', 'dog']):
row_ix = np.where(y == item[0])[0]
plt.scatter(X[row_ix, 0], X[row_ix, 1], label=animal)
plt.legend()
plt.show()