# Stage1_train_label. 400 x7 CSV (400 lines of seven columns), serial number of useless data is only the first column,
# Stage1_train_feature. 400 x73 CSV (400 lines, 73), useless data in the first column is the sequence number
# to convert RDD element to float type function
Def converttofloat (s) :
L=(float (I) for I in s)
Return the l
# read data sc. TextFile and remove the label and feature in the first column useless data
Data_train_label=sc. TextFile (r 'Stage1_train_label. CSV', 6, 0). The map (lambda row, row, the split (', ')). The map (lambda s: s [1]) # don't understand what meaning is 6, 0
Data_train_feature=sc. TextFile (r 'Stage1_train_feature. CSV', 72, 0). The map (lambda row, row, the split (', '). The map (lambda s: s [1])
Data_train_label_Sum=Data_train_label. The map (lambda s: (int (s [0]) + 2 * int [1] (s) + 4 * int [2] (s) + 10 * int [3] (s) + 20 * int [4] (s) + 40 * int [5] (s))) # more tag into a single label each tag has a weight respectively is 1,2,4,10,20,40
Data_train_feature=Data_train_feature. The map (converttofloat)
# merge data's goal is:
# will Data_train_label_Sum 400 elements, in turn, add to Data_train_feature 400 RDD last position within
Data_train=Data_train_feature. Union (Data_train_label_Sum)
Print Data_train. Collect ()
# results: Data_train_label_Sum 400 elements directly added to the Data_train_feature behind
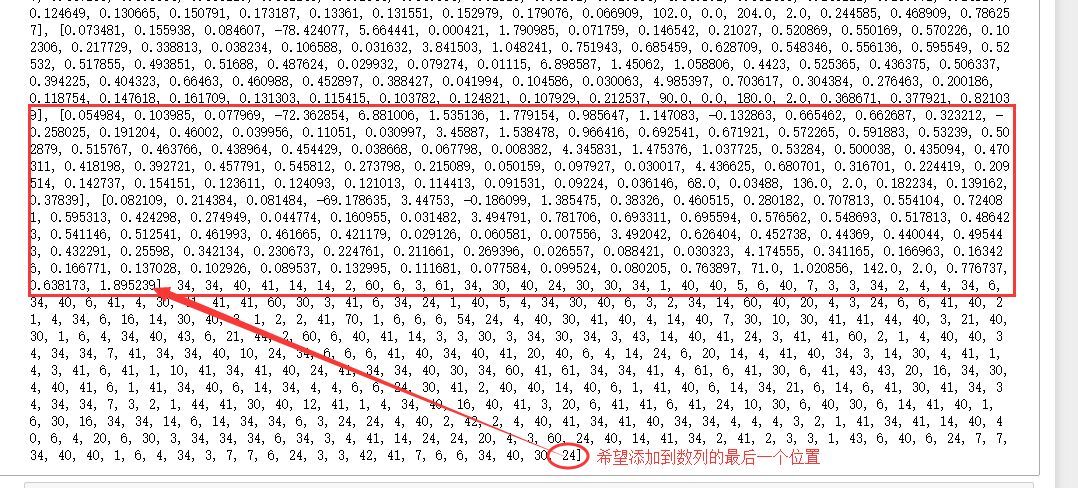
For such a simple question, I can't, try to access for a long time did not solve, finally summon up courage to post for help!!!!!
Ask everybody some directions how to implement last position the merger of the small white is added to the series in this thank you