I have an excel file. It has columns without a name. This columns are the next instance of the last named column. I would the columns without a name to be named after the last named column a counter of how many empty columns there were since the last named one.
I have something like this:
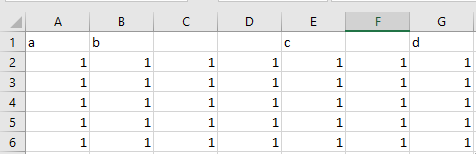
If I just read the .csv normally I get:
a b Unnamed: 2 Unnamed: 3 c Unnamed: 5 d
0 1 1 1 1 1 1 1
1 1 1 1 1 1 1 1
2 1 1 1 1 1 1 1
3 1 1 1 1 1 1 1
4 1 1 1 1 1 1 1
So I read with header=None, than I get the columns in the first row, where I can use ffill to fill them like I wish. The only I still want to add is a counter.
I would want my output to be like:
a b0 b1 b2 c0 c1 d
0 1 1 1 1 1 1 1
1 1 1 1 1 1 1 1
2 1 1 1 1 1 1 1
3 1 1 1 1 1 1 1
4 1 1 1 1 1 1 1
CodePudding user response:
First forward filling missing values create by Series.mask with ffill and then add counter:
s = df.columns.to_series()
df.columns = s.mask(s.str.startswith('Unnamed')).ffill()
#https://stackoverflow.com/a/61853830/2901002
from collections import defaultdict
renamer = defaultdict()
for column_name in df.columns[df.columns.duplicated(keep=False)].tolist():
if column_name not in renamer:
renamer[column_name] = [column_name '0']
else:
renamer[column_name].append(column_name str(len(renamer[column_name])))
df = df.rename(
columns=lambda column_name: renamer[column_name].pop(0)
if column_name in renamer
else column_name
)
print (df)
a b0 b1 b2 c0 c1 d
0 1 1 1 1 1 1 1
1 1 1 1 1 1 1 1
2 1 1 1 1 1 1 1
3 1 1 1 1 1 1 1
4 1 1 1 1 1 1 1
Another idea is use default pandas function for deduplicate columns names:
s = df.columns.to_series()
df.columns = s.mask(s.str.startswith('Unnamed')).ffill()
#https://stackoverflow.com/a/43792894/2901002
df.columns = pd.io.parsers.ParserBase({'names':df.columns})._maybe_dedup_names(df.columns)
print (df)
a b b.1 b.2 c c.1 d
0 1 1 1 1 1 1 1
1 1 1 1 1 1 1 1
2 1 1 1 1 1 1 1
3 1 1 1 1 1 1 1
4 1 1 1 1 1 1 1