I have a dataframe with multiple columns and I would like to remove rows that do not meet a certain condition. I would like to only keep the rows that have a -1 followed by a 1 in the dataframe in one of the columns.
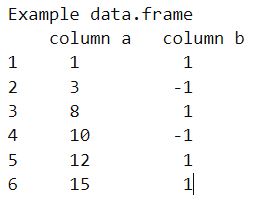
Example data.frame
column a column b
1 1 1
2 3 -1
3 8 1
4 10 -1
5 12 1
6 15 1
Example output:
column a column b
1 3 -1
2 8 1
3 10 -1
4 12 1

CodePudding user response:
With dplyr you can use:
library(dplyr)
your_data %>%
filter(
(`column b` == -1 & lead(`column b`) == 1) |
(`column b` == 1 & lag(`column b`) == -1)
)
# column a column b
# 2 3 -1
# 3 8 1
# 4 10 -1
# 5 12 1
Using this input data:
your_data = read.table(text = ' "column a" "column b"
1 1 1
2 3 -1
3 8 1
4 10 -1
5 12 1
6 15 1', header = T, check.names = FALSE)
CodePudding user response:
library(tidyverse)
df %>%
group_by(grp = cumsum(lead(df$column_b) == 1 & df$column_b == -1)) %>%
filter(grp > 0, row_number() %in% 1:2)
# A tibble: 4 x 3
# Groups: grp [2]
column_a column_b grp
<int> <int> <int>
1 3 -1 1
2 8 1 1
3 10 -1 2
4 12 1 2