I am trying to retrieve the first next Funded date for each row in a group. So for each row in a group, find the first closest funded date as long as its on or after the date.
Example dataset
import uuid
import pandas as pd
df = (
pd.DataFrame(
{
"id": pd.Series(
["A", "B", "C", "A", "B", "C", "A", "B", "C", "A", "B", "C","B"]
),
"status": pd.Series(
[
"Funded",
"Rejected",
"Rejected",
"Funded",
"Funded",
"Rejected",
"Rejected",
"Funded",
"Rejected",
"Rejected",
"Funded",
"Funded",
"Rejected"
]
),
"date": pd.Series(
[
"2021-01-31",
"2021-02-28",
"2021-03-31",
"2021-04-30",
"2021-05-31",
"2021-06-30",
"2021-07-31",
"2021-08-31",
"2021-09-30",
"2021-10-31",
"2021-11-30",
"2021-12-31",
"2021-07-15"
]
),
}
)
.sort_values(by=["id", "date"])
.reset_index(drop=True)
)
df["uuid"] = [uuid.uuid4() for x in range(len(df))]
expected output
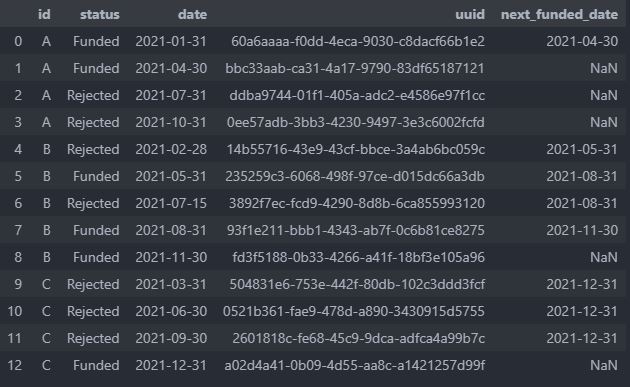
CodePudding user response:
Use pd.merge_asof:
# You should always convert datetime data to Timestamp type
df["date"] = pd.to_datetime(df["date"])
# For the left side of the merge: merge_asof requires the
# merge key to be sorted
left = df.sort_values("date")
# For the right side of the merge: it's a copy of the left
# side, but only for rows with status == Funded. We also
# rename the `date` column to `next_funded_date`
right = (
left.query("status == 'Funded'")
.rename(columns={"date": "next_funded_date"})
[["id", "next_funded_date"]]
)
# The merge: left and right side must match exactly on the
# `by` column, but can match "next nearest" on `left_on` and
# `right_on`
# direction = forward meaning left_on <= right_on
# allow_exact_matches=False disallows a row to match itself
pd.merge_asof(
left, right, by="id",
left_on="date", right_on="next_funded_date",
direction="forward", allow_exact_matches=False
).sort_values(["id", "date"])