I want to mark rows depending on other two columns. I must group and next mark.
I have the next dataframe:
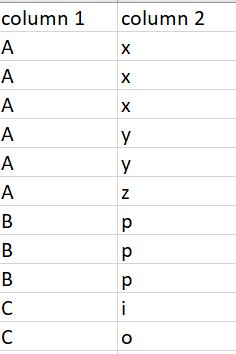
And I must do next:
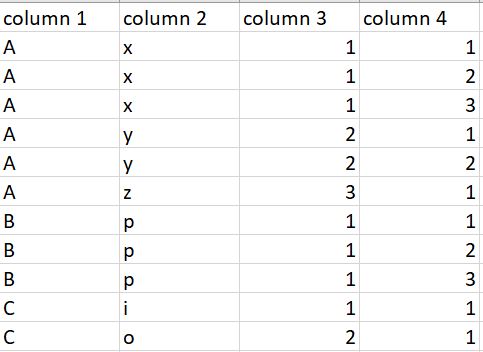 ]
]
The column_4 is done, I did next:
df['column_4'] = df.groupby(['column_1',"column_2"]).cumcount() 1
But I can't with column_3. Any solution?
CodePudding user response:
You can use shift ne to create a mask, and then groupby cumsum to turn it into numbers for your 3rd column:
df['column 4'] = df.groupby(['column 1', 'column 2']).cumcount().add(1)
df['column 3'] = df['column 2'].ne(df['column 2'].shift()).groupby(df['column 1']).cumsum()
Output:
>>> df
column 1 column 2 column 3 column 4
0 A x 1 1
1 A x 1 2
2 A x 1 3
3 A y 2 1
4 A y 2 2
5 A z 3 1
6 B p 1 1
7 B p 1 2
8 B p 1 3
9 C i 1 1
10 C o 2 1
CodePudding user response:
You could convert each group's col2 values to categorical and get the category codes.
import pandas as pd
df = pd.DataFrame({'column_1':['A','A','A','A','A','A','B','B','B','C','C'],
'column_2':['x','x','x','y','y','z','p','p','p','i','o']})
df['column_3'] = df.groupby('column_1')['column_2'].apply(lambda x: x.astype('category').cat.codes 1)
df['column_4'] = df.groupby(['column_1',"column_2"]).cumcount() 1
print(df)
Output
column_1 column_2 column_3 column_4
0 A x 1 1
1 A x 1 2
2 A x 1 3
3 A y 2 1
4 A y 2 2
5 A z 3 1
6 B p 1 1
7 B p 1 2
8 B p 1 3
9 C i 1 1
10 C o 2 1
CodePudding user response:
You can try group by column 1 and then group by column 2 in subgroup and use ngroup() to get group id.
df['column 3'] = df.groupby('column 1').apply(lambda group: group.groupby('column 2').ngroup() 1).droplevel(level=0)
print(df)
column 1 column 2 column 3
0 A x 1
1 A x 1
2 A x 1
3 A y 2
4 A y 2
5 A z 3
6 B p 1
7 B p 1
8 B p 1
9 C i 1
10 C o 2