I have some data about projects I would like to transform in a way that makes it easier to analyse with PowerBi.
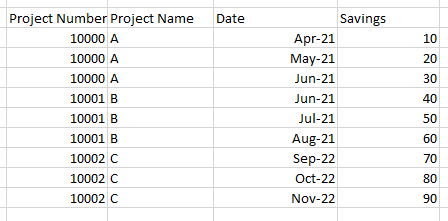
The data looks like this:

The so called 'SavingMonths' are values that correspond to the Project's performance and each sequential column represents the next month based on the project's start date.
For example, Project A starts in April 2021, therefore SavingsMonth1=April-21, SavingsMonth2=May-21... and so on.
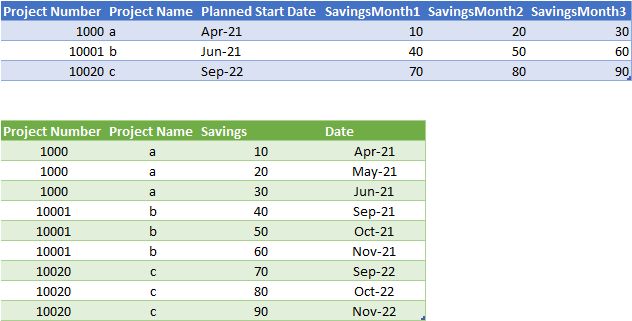
I would like to get it in this format:
In this way, I can now filter/sum 'Savings' column by date.
I'm not a programmer, but I do know some Python and thought the Pandas library may help, however I've only just started learning it and am looking for guidance as this is an urgent task. I don't know M at all, however I realised I can conduct transformations with Python in Power Query, which is nice.
Any help would be appreciated.
TIA
CodePudding user response:
The people responding to this question are mostly correct, it's almost an unpivot, with the exception of the incrementing months. We can use melt to unpivot, but then we have to add some date offsets to get the months right and then convert them back to the original format.
import pandas as pd
df = pd.DataFrame({'Project Number':[10000,10001,10002],
'Project Name':['A','B','C'],
'Planned Start Date':['Apr-21','Jun-21','Sep-22'],
'SavingsMonth1':[10,40,70],
'SavingsMonth2':[20,50,80],
'SavingsMonth3':[30,60,90]})
df['Planned Start Date'] = pd.to_datetime('01-' df['Planned Start Date'])
df.sort_values(by='Planned Start Date', inplace=True)
df = df.melt(id_vars=['Project Number','Project Name', 'Planned Start Date'], value_name='Savings')
df['offset'] = df['variable'].str.extract('(\d)').astype(int).sub(1)
df['Planned Start Date'] = (df['Planned Start Date'].dt.to_period('M') df['offset']).dt.strftime('%b-%y')
df = df.sort_values(by='Project Number').drop(columns=['variable','offset'])
print(df)
Output
Project Number Project Name Planned Start Date Savings
0 10000 A Apr-21 10
3 10000 A May-21 20
6 10000 A Jun-21 30
1 10001 B Jun-21 40
4 10001 B Jul-21 50
7 10001 B Aug-21 60
2 10002 C Sep-22 70
5 10002 C Oct-22 80
8 10002 C Nov-22 90
CodePudding user response:
In powerquery (M) assuming the date starts off as a text column this (a) unpivots (b) converts the text to a date (c) adds X months to that based off the number of original columns
let Source = Excel.CurrentWorkbook(){[Name="Table1"]}[Content],
#"Unpivoted Other Columns" = Table.UnpivotOtherColumns(Source, {"Project Number", "Project Name", "Planned Start Date"}, "Ignore", "Savings"),
#"Added Index" = Table.AddIndexColumn(#"Unpivoted Other Columns", "Index", 0, 1, Int64.Type),
#"Mod Index" = Table.TransformColumns(#"Added Index",{{"Index", each Number.Mod(_,List.Count(Table.ColumnNames(Source))-3), Int64.Type}}),
#"Split Column by Delimiter" = Table.SplitColumn(#"Mod Index", "Planned Start Date", Splitter.SplitTextByDelimiter("-", QuoteStyle.Csv), {"Planned Start Date.1", "Planned Start Date.2"}),
#"Added Custom1" = Table.AddColumn(#"Split Column by Delimiter", "Custom", each Date.FromText("01 "& [Planned Start Date.1] & "20"&[Planned Start Date.2])),
#"Added Custom" = Table.AddColumn(#"Added Custom1", "Date2", each Date.AddMonths([Custom],[Index])),
#"Added Custom2" = Table.AddColumn(#"Added Custom", "Date", each Date.ToText([Date2],"MMM-yy")),
#"Removed Other Columns" = Table.SelectColumns(#"Added Custom2",{"Project Number", "Project Name", "Savings", "Date"})
in #"Removed Other Columns"
CodePudding user response:
if you have the data in a csv you can load it into a pandas dataframe which will allow you to manipulate it easily
import pandas as pd
data = pd.read_csv('Path_to_where_data_is_saved.csv')
the data can be reformatted using the melt() function
data = pd.melt(data, id_vars=['Project Number', 'Project Name', 'Planned Start Date'])
this can then be saved back to a csv file
data.to_csv('path_to_save_results.csv')