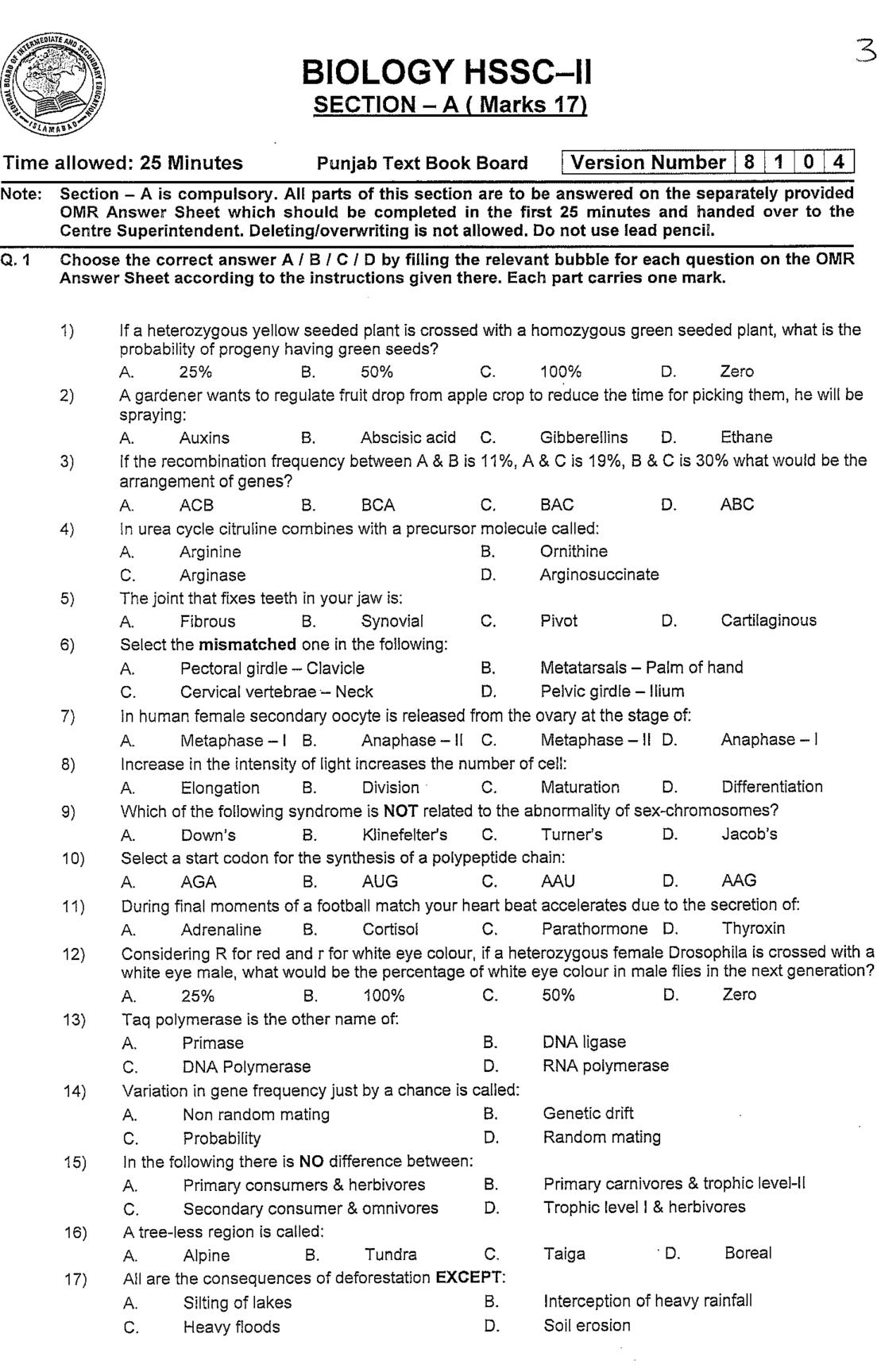
I want to crop the image to only extract the text sections. There are thousands of them with different sizes so I can't hardcode coordinates. I'm trying to remove the unwanted lines on the left and on the bottom. How can I do this?
| Original | Expected |
|---|---|
 |
 |
CodePudding user response:
Determine the least spanning bounding box by finding all the non-zero points in the image. Finally, crop your image using this bounding box. Finding the contours is time-consuming and unnecessary here, especially because your text is axis-aligned. You may accomplish your goal by combining cv2.findNonZero and cv2.boundingRect.
Hope this will work ! :
import numpy as np
import cv2
img = cv2.imread(r"W430Q.png")
# Read in the image and convert to grayscale
img = img[:-20, :-20] # Perform pre-cropping
gray = cv2.cvtColor(img, cv2.COLOR_BGR2GRAY)
gray = 255*(gray < 50).astype(np.uint8) # To invert the text to white
gray = cv2.morphologyEx(gray, cv2.MORPH_OPEN, np.ones(
(2, 2), dtype=np.uint8)) # Perform noise filtering
coords = cv2.findNonZero(gray) # Find all non-zero points (text)
x, y, w, h = cv2.boundingRect(coords) # Find minimum spanning bounding box
# Crop the image - note we do this on the original image
rect = img[y:y h, x:x w]
cv2.imshow("Cropped", rect) # Show it
cv2.waitKey(0)
cv2.destroyAllWindows()
in above code from forth line of code is where I set the threshold below 50 to make the dark text white. However, because this outputs a binary image, I convert to uint8, then scale by 255. The text is effectively inverted.
Then, using cv2.findNonZero, we discover all of the non-zero locations for this image.We then passed this to cv2.boundingRect, which returns the top-left corner of the bounding box, as well as its width and height. Finally, we can utilise this to crop the image. This is done on the original image, not the inverted version.
CodePudding user response:
Here's a simple approach:
Obtain binary image.


Dilate to combine into a single contour
->Detected ROI to extract in green3 4 

Result
Code
import cv2 import numpy as np # Load image, grayscale, Gaussian blur, Otsu's threshold image = cv2.imread('1.png') original = image.copy() gray = cv2.cvtColor(image, cv2.COLOR_BGR2GRAY) blur = cv2.GaussianBlur(gray, (3, 3), 0) thresh = cv2.threshold(blur, 0, 255, cv2.THRESH_BINARY_INV cv2.THRESH_OTSU)[1] # Remove horizontal lines horizontal_kernel = cv2.getStructuringElement(cv2.MORPH_RECT, (25,1)) detected_lines = cv2.morphologyEx(thresh, cv2.MORPH_OPEN, horizontal_kernel, iterations=1) cnts = cv2.findContours(detected_lines, cv2.RETR_EXTERNAL, cv2.CHAIN_APPROX_SIMPLE) cnts = cnts[0] if len(cnts) == 2 else cnts[1] for c in cnts: cv2.drawContours(thresh, [c], -1, 0, -1) # Dilate to merge into a single contour vertical_kernel = cv2.getStructuringElement(cv2.MORPH_RECT, (2,30)) dilate = cv2.dilate(thresh, vertical_kernel, iterations=3) # Find contours, sort for largest contour and extract ROI cnts, _ = cv2.findContours(dilate, cv2.RETR_EXTERNAL, cv2.CHAIN_APPROX_SIMPLE)[-2:] cnts = sorted(cnts, key=cv2.contourArea, reverse=True)[:-1] for c in cnts: x,y,w,h = cv2.boundingRect(c) cv2.rectangle(image, (x, y), (x w, y h), (36,255,12), 4) ROI = original[y:y h, x:x w] break cv2.imshow('image', image) cv2.imshow('dilate', dilate) cv2.imshow('thresh', thresh) cv2.imshow('ROI', ROI) cv2.waitKey()