I am trying to create an efficient loss function for the following problem:
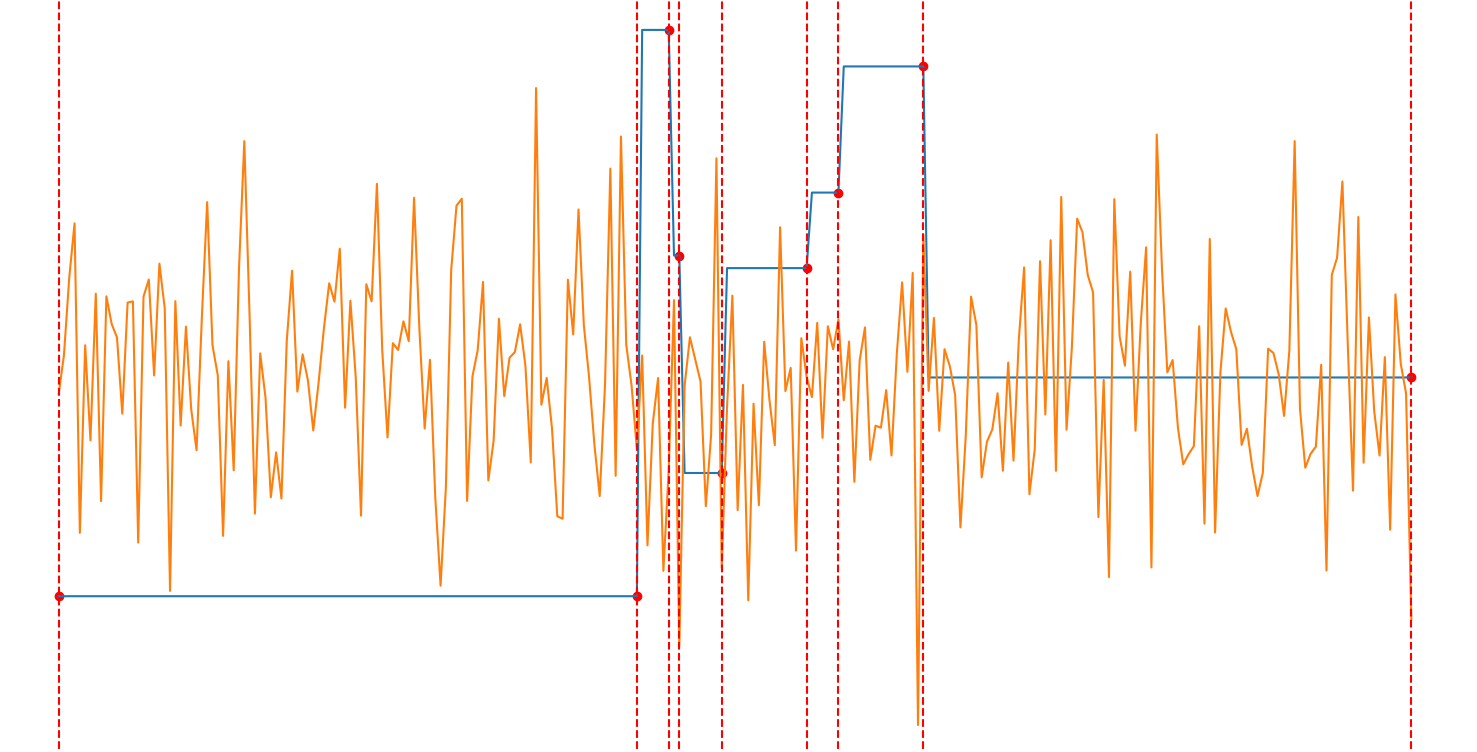 The loss is a sum of MAE calculated for each range between the red lines. The blue line is the ground truth, the orange line is a prediction, and the red dots mark the index where the value of the ground truth changes from one to another and close the current value range. Values of inputs are within the [0,1] range. The number of value ranges varies; it can be something between 2-12.
The loss is a sum of MAE calculated for each range between the red lines. The blue line is the ground truth, the orange line is a prediction, and the red dots mark the index where the value of the ground truth changes from one to another and close the current value range. Values of inputs are within the [0,1] range. The number of value ranges varies; it can be something between 2-12.
Previously, I made a code with TF map_fn but it was VERY slow:
def rwmae_old(y_true, y_pred):
y_pred = tf.convert_to_tensor(y_pred)
y_true = tf.cast(y_true, y_pred.dtype)
# prepare array
yt_tmp = tf.concat(
[tf.ones([len(y_true), 1], dtype=y_pred.dtype) * tf.cast(len(y_true), dtype=y_true.dtype), y_true], axis=-1)
yt_tmp = tf.concat([yt_tmp, tf.ones([len(y_true), 1]) * tf.cast(len(y_true), dtype=y_true.dtype)], axis=-1)
# find where there is a change of values between consecutive indices
ranges = tf.transpose(tf.where(yt_tmp[:, :-1] != yt_tmp[:, 1:]))
ranges_cols = tf.concat(
[[0], tf.transpose(tf.where(ranges[1][1:] == 0))[0] 1, [tf.cast(len(ranges[1]), dtype=y_true.dtype)]], axis=0)
ranges_rows = tf.range(len(y_true))
losses = tf.map_fn(
# loop through every row in the array
lambda ii:
tf.reduce_mean(
tf.map_fn(
# loop through every range within the example and calculate the loss
lambda jj:
tf.reduce_mean(
tf.abs(
y_true[ii][ranges[1][ranges_cols[ii] jj]: ranges[1][ranges_cols[ii] jj 1]] -
y_pred[ii][ranges[1][ranges_cols[ii] jj]: ranges[1][ranges_cols[ii] jj 1]]
),
),
tf.range(ranges_cols[ii 1] - ranges_cols[ii] - 1),
fn_output_signature=y_pred.dtype
)
),
ranges_rows,
fn_output_signature=y_pred.dtype
)
return losses
Today, I created a lazy code that just goes through every example in the batch and checks if values change between indices and, if so, calculates MAE for the current range:
def rwmae(y_true, y_pred):
(batch_size, length) = y_pred.shape
losses = tf.zeros(batch_size, dtype=y_pred.dtype)
for ii in range(batch_size):
# reset loss for the current row
loss = tf.constant(0, dtype=y_pred.dtype)
# set current range start index to 0
ris = 0
for jj in range(length - 1):
if y_true[ii][jj] != y_true[ii][jj 1]:
# we found a point of change, calculate the loss in the current range and ...
loss = tf.add(loss, tf.reduce_mean(tf.abs(y_true[ii][ris: jj 1] - y_pred[ii][ris: jj 1])))
# ... update the new range starting point
ris = jj 1
if ris != length - 1:
# we need to calculate the loss for the rest of the vector
loss = tf.add(loss, tf.reduce_mean(tf.abs(y_true[ii][ris: length] - y_pred[ii][ris: length])))
#replace loss in the proper row
losses = tf.tensor_scatter_nd_update(losses, [[ii]], [loss])
return losses
Do you think there is any way to improve its efficiency? Or maybe you think there is a better loss function for the problem?
CodePudding user response:
You can try something like this:
import numpy as np
import tensorflow as tf
def rwmae(y_true, y_pred):
(batch_size, length) = tf.shape(y_pred)
losses = tf.zeros(batch_size, dtype=y_pred.dtype)
for ii in tf.range(batch_size):
ris = 0
indices= tf.concat([tf.where(y_true[ii][:-1] != y_true[ii][1:])[:, 0], [length-1]], axis=0)
ragged_indices = tf.ragged.range(tf.concat([[ris], indices[:-1] 1], axis=0), indices 1)
loss = tf.reduce_sum(tf.reduce_mean(tf.abs(tf.gather(y_true[ii], ragged_indices) - tf.gather(y_pred[ii], ragged_indices)), axis=-1, keepdims=True))
losses = tf.tensor_scatter_nd_update(losses, [[ii]], [tf.math.divide_no_nan(loss, tf.cast(tf.shape(indices)[0], dtype=tf.float32))])
return losses
data = np.load('/content/data.npy', allow_pickle=True)
y_pred = data[0:2][0]
y_true = data[0:2][1]
print(rwmae(y_true, y_pred), y_true.shape)