I have the following json file
{
"matches": [
{
"team": "Sunrisers Hyderabad",
"overallResult": "Won",
"totalMatches": 3,
"margins": [
{
"bar": 290
},
{
"bar": 90
}
]
},
{
"team": "Pune Warriors",
"overallResult": "None",
"totalMatches": 0,
"margins": null
}
],
"totalMatches": 70
}
Note - Above json is fragment of original json. The actual file contains lot more attributes after 'margins', some of them nested and others not so. I just put some for brevity and to give an idea of expectations.
My goal is to flatten the data and load it into CSV. Here is the code I have written so far -
import json
import pandas as pd
path = r"/Users/samt/Downloads/test_data.json"
with open(path) as f:
t_data = {}
data = json.load(f)
for team in data['matches']:
if team['margins']:
for idx, margin in enumerate(team['margins']):
t_data['team'] = team['team']
t_data['overallResult'] = team['overallResult']
t_data['totalMatches'] = team['totalMatches']
t_data['margin'] = margin.get('bar')
else:
t_data['team'] = team['team']
t_data['overallResult'] = team['overallResult']
t_data['totalMatches'] = team['totalMatches']
t_data['margin'] = margin.get('bar')
df = pd.DataFrame.from_dict(t_data, orient='index')
print(df)
I know that data is getting over-written and loop is not properly structured.I am bit new to dealing with JSON objects using Python and I am not able to understand how to concate the results.
My goal is once, all the results are appended, use to_csv and convert them into rows. For each margin, the entire data is to be replicated as a seperate row. Here is what I am expecting the output to be. Can someone please help how to translate this?
From whatever I find on the net, it is about first gathering the dictionary items but how to transpose it to rows is something I am not able to understand. Also, is there a better way to parse the json than doing the loop twice for one attribute i.e. margins?
I can't use json_normalize as that library is not supported in our environment.
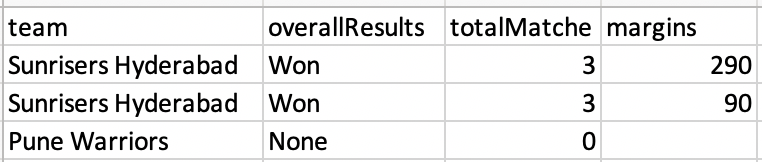
[output data]
CodePudding user response:
You can use pd.DataFrame to create DataFrame and explode the margins column
import json
import pandas as pd
with open('data.json', 'r', encoding='utf-8') as f:
data = json.loads(f.read())
df = pd.DataFrame(data['matches']).explode('margins', ignore_index=True)
print(df)
team overallResult totalMatches margins
0 Sunrisers Hyderabad Won 3 {'bar': 290}
1 Sunrisers Hyderabad Won 3 {'bar': 90}
2 Pune Warriors None 0 None
Then fill the None value in margins column to dictionary and convert it to column
bar = df['margins'].apply(lambda x: x if x else {'bar': pd.NA}).apply(pd.Series)
print(bar)
bar
0 290
1 90
2 <NA>
At last, join the Series to original dataframe
df = df.join(bar).drop(columns='margins')
print(df)
team overallResult totalMatches bar
0 Sunrisers Hyderabad Won 3 290
1 Sunrisers Hyderabad Won 3 90
2 Pune Warriors None 0 <NA>
CodePudding user response:
Using the json and csv modules: create a dictionary for each team, for each margin if there is one.
import json, csv
s = '''{
"matches": [
{
"team": "Sunrisers Hyderabad",
"overallResult": "Won",
"totalMatches": 3,
"margins": [
{
"bar": 290
},
{
"bar": 90
}
]
},
{
"team": "Pune Warriors",
"overallResult": "None",
"totalMatches": 0,
"margins": null
}
],
"totalMatches": 70
}'''
j = json.loads(s)
matches = j['matches']
rows = []
for thing in matches:
# print(thing)
if not thing['margins']:
rows.append(thing)
else:
for bar in (b['bar'] for b in thing['margins']):
d = dict((k,thing[k]) for k in ('team','overallResult','totalMatches'))
d['margins'] = bar
rows.append(d)
# for row in rows: print(row)
# using an in-memory stream for this example instead of an actual file
import io
f = io.StringIO(newline='')
fieldnames=('team','overallResult','totalMatches','margins')
writer = csv.DictWriter(f,fieldnames=fieldnames)
writer.writeheader()
writer.writerows(rows)
f.seek(0)
print(f.read())
team,overallResult,totalMatches,margins
Sunrisers Hyderabad,Won,3,290
Sunrisers Hyderabad,Won,3,90
Pune Warriors,None,0,
Getting multiple item values from a dictionary can be aided by using operator.itemgetter()
>>> import operator
>>> items = operator.itemgetter(*('team','overallResult','totalMatches'))
>>> #items = operator.itemgetter('team','overallResult','totalMatches')
>>> #stuff = ('team','overallResult','totalMatches'))
>>> #items = operator.itemgetter(*stuff)
>>> d = {'margins': 90,
... 'overallResult': 'Won',
... 'team': 'Sunrisers Hyderabad',
... 'totalMatches': 3}
>>> items(d)
('Sunrisers Hyderabad', 'Won', 3)
>>>
I like to use use it and give the callable a descriptive name but I don't see it used much here on SO.